硬件支持和BIOS设置
Intel(R) VT for Directed I/O
宿主机内核的配置
CONFIG_INTEL_IOMMU=y
CONFIG_DMAR=y
CONFIG_PCI_STUB=y // 隐藏设备
在启动宿主机系统后,可以通过内核的打印信息来检查 VT-d 是否处于打开可用状态,如下图所示:
# dmesg | grep DMAR -i
# dmesg | grep IOMMU -i
menuentry 'Red Hat Enterprise Linux Server (4.6.0+) 7.2 (Maipo)' --class red --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-3.10.0-327.el7.x86_64-advanced-86ddb3e6-07fc-47a9-9e69-d1591ca0942b' {
load_video
set gfxpayload=keep
insmod gzio
insmod part_msdos
insmod xfs
set root='hd0,msdos1'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd0,msdos1 --hint-efi=hd0,msdos1 --hint-baremetal=ahci0,msdos1 --hint='hd0,msdos1' ef9ce169-d238-44a7-bebb-99bc2805a0c0
else
search --no-floppy --fs-uuid --set=root ef9ce169-d238-44a7-bebb-99bc2805a0c0
fi
linux16 /vmlinuz-4.6.0+ root=/dev/mapper/rhel-root ro crashkernel=auto rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet LANG=en_US.UTF-8 intel_iommu=on
initrd16 /initramfs-4.6.0+.img
}
modprobe vfio-pci or
modprobe pci_stub
ls /sys/bus/pci/drivers/pci-stub/
modprobe vfio-pci
For Xen:
# ethtool -i eth0
0000:01:00.0 ($bdf)
# xl pci-assignable-add $bdf
or # ethtool -i eth0 # lspci -Dn -s “$bdf” | awk ‘{print $3}’ | sed “s/:/ /” 8086 105e ($pciid) # echo -n “$pciid” > /sys/bus/pci/drivers/pci-stub/new_id # echo -n “$bdf” > /sys/bus/pci/devices/”$bdf”/driver/unbind # echo -n “$bdf” > /sys/bus/pci/drivers/pci-stub/bind
在绑定前,用 lspci 命令查看BDF为 08:00.0的设备使用的驱动是 Intel 的 e1000e驱动,而绑定到 pci_stub 后,通过如下命令可以查看它目前使用驱动是 pci_stub 而不是 e1000e了,其中 lspci -k 选项表示输出信息中显示正在使用的驱动和内核中可以支持该设备的模块。
# lspci -k -s 08:00.0
For KVM:
# ethtool -i eth0
0000:01:00.0 ($bdf)
# lspci -Dn -s "$bdf" | awk '{print $3}' | sed "s/:/ /"
8086 105e ($pciid)
8086(Vender ID) 105e(Device ID)
# echo -n "$pciid" > /sys/bus/pci/drivers/vfio-pci/new_id
# echo -n "$bdf" > /sys/bus/pci/devices/"$bdf"/driver/unbind
# echo -n "$bdf" > /sys/bus/pci/drivers/vfio-pci/bind
通过 QEMU命令行分配设备给客户机
# qemu-system-x86_64 -device ? (这里的问号可以查看有哪些可用的驱动)
# qemu-system-x86_64 rhel6u3.img -m 1024 -device pci-assign,host=08:00.0,id=mydev0,addr=0x6
我们也可以在QEMU中采用 info pci 查看 pci 的相关设备。
For Xen:
# xl pci-assignable-remove $bdf
# echo -n "$bdf" > /sys/bus/pci/drivers/e1000e/bind
For KVM:
# echo -n "$bdf" > /sys/bus/pci/drivers/vfio-pci/unbind
# echo -n "$bdf" > /sys/bus/pci/drivers/e1000e/bind
vim kvm-rhel7-epc-passthrough.sh
# !/bin/sh
qemu-system-x86_64 -enable-kvm -m 4096 -smp 4 -cpu host \
-device virtio-net-pci,netdev=nic0,mac=00:16:3e:0c:12:78 \
-netdev tap,id=nic0,script=/etc/kvm/qemu-ifup \
-drive file=/root/ubuntu_sgx.qcow2,if=none,id=virtio-disk0 \
-device virtio-blk-pci,drive=virtio-disk0 \
-device vfio-pci,host=01:00.0 -net none
or -device pci-assign,host=01:00.0,id=mynic -net none
vim xen-rhel7-epc-passthrough.conf
builder= "hvm"
name= "vm1"
memory = 4096
vcpus=16
vif = [ 'type=ioemu, mac=00:16:3e:14:e4:d4, bridge=xenbr0' ]
disk = [ '/root/rhel7u2_xen_sgx.qcow2,qcow2,sda,rw' ]
vnc=1
stdvga=1
acpi=1
hpet=1
pci= [ ‘01:00.0’ ]
在QEMU/KVM中,客户机能使用的设备,大致可分为如下三种类型。
模拟I/O设备方式的优点是对硬件平台依赖性较低、可以方便模拟一些流行的和较老久的设备、不需要宿主机和客户机的额外支持,故兼容性高;而其缺点是I/O路径较长、VM-Exit次数很多,故性能较差。一般适用于对I/O性能要求不高的场景,或者模拟一些老旧遗留(legacy)设备(如RTL8139的网卡)。
Virtio半虚拟化设备方式的优点是实现了VIRTIO API,减少了VM-Exit次数,提高了客户机I/O执行效率,比普通模拟I/O的效率高很多;而其缺点是需要客户机中virtio相关驱动的支持(较老的系统默认没有自带这些驱动,Windows系统中需要额外安装virtio驱动),故兼容性较差,而且I/O频繁时的CPU使用率较高。
而第3种方式叫做PCI设备直接分配(Device Assignment,或者PCI pass-through),它允许将宿主机中的物理PCI(或PCI-E)设备直接分配给客户机完全使用,正是本节要介绍的重点内容。较新的x86架构的主要硬件平台(包括服务器级、桌面级)都已经支持设备直接分配,其中Intel定义的I/O虚拟化技术规范为“Intel(R) Virtualization Technology for Directed I/O”(VT-d),而AMD的为“AMD-V”(也叫做IOMMU)。本节以KVM中使用Intel VT-d技术为例来进行介绍(当然AMD IOMMU也是类似的)。
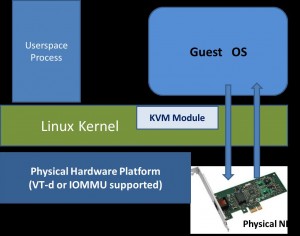
KVM虚拟机支持将宿主机中的PCI、PCI-E设备附加到虚拟化的客户机中,从而让客户机以独占方式访问这个PCI(或PCI-E)设备。通过硬件支持的VT-d技术将设备分配给客户机后,在客户机看来,设备是物理上连接在其PCI(或PCI-E)总线上的,客户机对该设备的I/O交互操作和实际的物理设备操作完全一样,这不需要(或者很少需要)Hypervisor(即KVM)的参与。KVM中通过VT-d技术使用一个PCI-E网卡的系统架构示例如下图所示
运行在支持VT-d平台上的QEMU/KVM,可以分配网卡、磁盘控制器、USB控制器、VGA显卡等给客户机直接使用。而为了设备分配的安全性,它还需要中断重映射(interrupt remapping)的支持,尽管QEMU命令行进行设备分配时并不直接检查中断重映射功能是否开启,但是在通过一些工具使用KVM时(如RHEL6.3中的libvirt)默认需要有中断重映射的功能支持,才能使用VT-d分配设备给客户机使用。
设备直接分配让客户机完全占有PCI设备,在执行I/O操作时大量地减少了(甚至避免)了VM-Exit陷入到Hypervisor中,极大地提高了I/O性能,可以达到和Native系统中几乎一样的性能。尽管Virtio的性能也不错,但VT-d克服了其兼容性不够好和CPU使用率较高的问题。不过,VT-d也有自己的缺点,一台服务器主板上的空间比较有限,允许添加的PCI和PCI-E设备是有限的,如果一个宿主机上有较多数量的客户机,则很难给每个客户机都独立分配VT-d的设备。另外,大量使用VT-d独立分配设备给客户机,让硬件设备数量增加,故增加了硬件投资成本。 为了避免这两个缺点,可以考虑采用如下两个方案。一是,在一个物理宿主机上,仅给少数的对I/O(如网络)性能要求较高的客户机使用VT-d直接分配设备(如网卡),而其余的客户机使用纯模拟(emulated)或使用Virtio以达到多个客户机共享同一个设备的目的。二是,对于网络I/O的解决方法,可以选择SR-IOV让一个网卡产生多个独立的虚拟网卡,将每个虚拟网卡分别分配给一个客户机使用,这也正是后面“SR-IOV技术”这一小节要介绍的内容。另外,它还有一个缺点是,对于使用VT-d直接分配了设备的客户机,其动态迁移功能将会受限,不过也可以在用bonding驱动等方式来缓解这个问题,将在“动态迁移”小节较为详细介绍此方法。
在现代计算机系统中,一般 SATA或SAS等类型硬盘的控制器都是接入到PCI(PCIe)总线上的,所以也可以将硬盘作为普通的PCI设备直接分配给客户机使用。不过当 SATA或SAS设备直接分配给虚拟机时实际上将其控制器作为一个整体分配到客户机中,如果宿主机使用的硬盘也连接在同一个SATA和SAS控制器上,则不能将该控制器直接分配给客户机,而是需要硬件平台中至少有两个控制器。
a. 查看宿主机硬盘设备,并隐藏
ll /dev/disk/by-path/pci-0000\:16\:00.0-sas-0x12210000000000-lun-0
ll /dev/dsik/by-path/pci-0000\:00\:1f.2-scsi-0\:0\:0\:0\:0
lspci -k -s $bdf1
lspci -k -s $bdf2
fdisk -l /dev/sdb
df -h
./pci_stub.sh -h $bdf2
lspci -k -s $bdf2
b. 将 sata 硬盘分配给客户机使用
qemu-system-x86_64 rhel6u3.img -smp 2 -m 1024 -device pci-assign,host=$bdf2,addr=0x6 -net nic -net tap
c. 在客户机中查看硬盘
fdisk -l /dev/sfb
ll /dev/dsik/by-path/pci-0000\:00\:04.0-scsi-2\:0\:0\:0\:0
lspci -k -s 00:06.0
如果是U盘,基本和硬盘差不多,不再叙述 如果分配的 SandDisk 的U盘设备
lsusb
qemu-system-x86_64 rhel6u3.img -smp 2 -m 1024 -usbdevice host=0781:5667 -net nic -net tap
dmesg | grep -e Keyboard -e Mouse
lsusb
lspci | grep -i VGA
qemu-system-x86_64 rhel6u3.img -smp 2 -m 1024 -device pci-assign,host=$bdf_usb \
-device pci-assign,host=$bdf_vga -net nic -net tap
VFIO是一套用户态驱动框架,它提供两种基本服务:
VFIO由平台无关的接口层与平台相关的实现层组成。接口层将服务抽象为IOCTL命令,规化操作流程,定义通用数据结构,与用户态交互。实现层完成承诺的服务。据此,可在用户态实现支持DMA操作的高性能驱动。在虚拟化场景中,亦可借此完全在用户态实现device passthrough。
VFIO实现层又分为设备实现层与IOMMU实现层。当前VFIO仅支持PCI设备。IOMMU实现层则有x86与PowerPC两种。VFIO设计灵活,可以很方便地加入对其它种类硬件及IOMMU的支持。
与KVM一样,用户态通过IOCTL与VFIO交互。可作为操作对象的几种文件描述符有:
Container文件描述符
打开/dev/vfio字符设备可得
IOMMU group文件描述符
打开/dev/vfio/N文件可得 (详见后文)
Device文件描述符
向IOMMU group文件描述符发起相关ioctl可得
逻辑上来说,IOMMU group是IOMMU操作的最小对象。某些IOMMU硬件支持将若干IOMMU group组成更大的单元。VFIO据此做出container的概念,可容纳多个IOMMU group。打开/dev/vfio文件即新建一个空的container。在VFIO中,container是IOMMU操作的最小对象。
要使用VFIO,需先将设备与原驱动拨离,并与VFIO绑定。
用VFIO访问硬件的步骤:
用VFIO配置IOMMU的步骤:
VFIO设备实现层与Linux设备模型紧密相连,当前,VFIO中仅有针对PCI的设备实现层(实现在vfio-pci模块中)。设备实现层的作用与普通设备驱动的作用类似。普通设备驱动向上穿过若干抽象层,最终以Linux里广为人知的抽象设备(网络设备,块设备等等)展现于世。VFIO设备实现层在/dev/vfio/目录下为设备所在IOMMU group生成相关文件,继而将设备暴露出来。两者起点相同,最终呈现给用户态不同的接口。欲使设备置于VFIO管辖之下,需将其与旧驱动解除绑定,由VFIO设备实现层接管。用户态能感知到的,是一个设备的消失(如eth0),及/dev/vfio/N文件的诞生(其中N为设备所在IOMMU group的序号)。由于IOMMU group内的设备相互影响,只有组内全部设备被VFIO管理时,方能经VFIO配置此IOMMU group。
把设备归于IOMMU group的策略由平台决定。在PowerNV平台,一个IOMMU group与一个PE对应。PowerPC平台不支持将多个IOMMU group作为更大的IOMMU操作单元,故而container只是IOMMU group的简单包装而已。对container进行的IOMMU操作最终会被路由至底层的IOMMU实现层,这实际上将用户态与内核里的IOMMU驱动接连了起来。
https://www.kernel.org/doc/Documentation/vfio.txt
Many modern system now provide DMA and interrupt remapping facilities to help ensure I/O devices behave within the boundaries they’ve been allotted. This includes x86 hardware with AMD-Vi and Intel VT-d, POWER systems with Partitionable Endpoints (PEs) and embedded PowerPC systems such as Freescale PAMU. The VFIO driver is an IOMMU/device agnostic framework for exposing direct device access to userspace, in a secure, IOMMU protected environment. In other words, this allows safe[2], non-privileged, userspace drivers.
Why do we want that? Virtual machines often make use of direct device access (“device assignment”) when configured for the highest possible I/O performance. From a device and host perspective, this simply turns the VM into a userspace driver, with the benefits of significantly reduced latency, higher bandwidth, and direct use of bare-metal device drivers[3].
Some applications, particularly in the high performance computing field, also benefit from low-overhead, direct device access from userspace. Examples include network adapters (often non-TCP/IP based) and compute accelerators. Prior to VFIO, these drivers had to either go through the full development cycle to become proper upstream driver, be maintained out of tree, or make use of the UIO framework, which has no notion of IOMMU protection, limited interrupt support, and requires root privileges to access things like PCI configuration space.
The VFIO driver framework intends to unify these, replacing both the KVM PCI specific device assignment code as well as provide a more secure, more featureful userspace driver environment than UIO.
Devices are the main target of any I/O driver. Devices typically create a programming interface made up of I/O access, interrupts, and DMA. Without going into the details of each of these, DMA is by far the most critical aspect for maintaining a secure environment as allowing a device read-write access to system memory imposes the greatest risk to the overall system integrity.
To help mitigate this risk, many modern IOMMUs now incorporate isolation properties into what was, in many cases, an interface only meant for translation (ie. solving the addressing problems of devices with limited address spaces). With this, devices can now be isolated from each other and from arbitrary memory access, thus allowing things like secure direct assignment of devices into virtual machines.
This isolation is not always at the granularity of a single device though. Even when an IOMMU is capable of this, properties of devices, interconnects, and IOMMU topologies can each reduce this isolation. For instance, an individual device may be part of a larger multi- function enclosure. While the IOMMU may be able to distinguish between devices within the enclosure, the enclosure may not require transactions between devices to reach the IOMMU. Examples of this could be anything from a multi-function PCI device with backdoors between functions to a non-PCI-ACS (Access Control Services) capable bridge allowing redirection without reaching the IOMMU. Topology can also play a factor in terms of hiding devices. A PCIe-to-PCI bridge masks the devices behind it, making transaction appear as if from the bridge itself. Obviously IOMMU design plays a major factor as well.
Therefore, while for the most part an IOMMU may have device level granularity, any system is susceptible to reduced granularity. The IOMMU API therefore supports a notion of IOMMU groups. A group is a set of devices which is isolatable from all other devices in the system. Groups are therefore the unit of ownership used by VFIO.
While the group is the minimum granularity that must be used to ensure secure user access, it’s not necessarily the preferred granularity. In IOMMUs which make use of page tables, it may be possible to share a set of page tables between different groups, reducing the overhead both to the platform (reduced TLB thrashing, reduced duplicate page tables), and to the user (programming only a single set of translations). For this reason, VFIO makes use of a container class, which may hold one or more groups. A container is created by simply opening the /dev/vfio/vfio character device.
On its own, the container provides little functionality, with all but a couple version and extension query interfaces locked away. The user needs to add a group into the container for the next level of functionality. To do this, the user first needs to identify the group associated with the desired device. This can be done using the sysfs links described in the example below. By unbinding the device from the host driver and binding it to a VFIO driver, a new VFIO group will appear for the group as /dev/vfio/$GROUP, where $GROUP is the IOMMU group number of which the device is a member. If the IOMMU group contains multiple devices, each will need to be bound to a VFIO driver before operations on the VFIO group are allowed (it’s also sufficient to only unbind the device from host drivers if a VFIO driver is unavailable; this will make the group available, but not that particular device). TBD - interface for disabling driver probing/locking a device.
Once the group is ready, it may be added to the container by opening the VFIO group character device (/dev/vfio/$GROUP) and using the VFIO_GROUP_SET_CONTAINER ioctl, passing the file descriptor of the previously opened container file. If desired and if the IOMMU driver supports sharing the IOMMU context between groups, multiple groups may be set to the same container. If a group fails to set to a container with existing groups, a new empty container will need to be used instead.
With a group (or groups) attached to a container, the remaining ioctls become available, enabling access to the VFIO IOMMU interfaces. Additionally, it now becomes possible to get file descriptors for each device within a group using an ioctl on the VFIO group file descriptor.
The VFIO device API includes ioctls for describing the device, the I/O regions and their read/write/mmap offsets on the device descriptor, as well as mechanisms for describing and registering interrupt notifications.
Assume user wants to access PCI device 0000:06:0d.0
$ readlink /sys/bus/pci/devices/0000:06:0d.0/iommu_group ../../../../kernel/iommu_groups/26
This device is therefore in IOMMU group 26. This device is on the pci bus, therefore the user will make use of vfio-pci to manage the group:
$ modprobe vfio-pci
Binding this device to the vfio-pci driver creates the VFIO group character devices for this group:
$ lspci -n -s 0000:06:0d.0 06:0d.0 0401: 1102:0002 (rev 08) $ echo 0000:06:0d.0 > /sys/bus/pci/devices/0000:06:0d.0/driver/unbind $ echo 1102 0002 > /sys/bus/pci/drivers/vfio-pci/new_id
Now we need to look at what other devices are in the group to free it for use by VFIO:
$ ls -l /sys/bus/pci/devices/0000:06:0d.0/iommu_group/devices total 0 lrwxrwxrwx. 1 root root 0 Apr 23 16:13 0000:00:1e.0 -> ../../../../devices/pci0000:00/0000:00:1e.0 lrwxrwxrwx. 1 root root 0 Apr 23 16:13 0000:06:0d.0 -> ../../../../devices/pci0000:00/0000:00:1e.0/0000:06:0d.0 lrwxrwxrwx. 1 root root 0 Apr 23 16:13 0000:06:0d.1 -> ../../../../devices/pci0000:00/0000:00:1e.0/0000:06:0d.1
This device is behind a PCIe-to-PCI bridge[4], therefore we also need to add device 0000:06:0d.1 to the group following the same procedure as above. Device 0000:00:1e.0 is a bridge that does not currently have a host driver, therefore it’s not required to bind this device to the vfio-pci driver (vfio-pci does not currently support PCI bridges).
The final step is to provide the user with access to the group if unprivileged operation is desired (note that /dev/vfio/vfio provides no capabilities on its own and is therefore expected to be set to mode 0666 by the system).
$ chown user:use
VFIO是一套用户态驱动框架,可用于编写高效用户态驱动;在虚拟化情景下,亦可用来在用户态实现device passthrough。通过VFIO访问硬件并无新意,VFIO可贵之处在于第一次向用户态开放了IOMMU接口,能完全在用户态配置IOMMU,将DMA地址空间映射进而限制在进程虚拟地址空间之内。这对高性能用户态驱动以及在用户态实现device passthrough意义重大。