IO(输入输出)是 CPU 访问外部设备的方法。设备通常通过寄存器和设备RAM将自身功能展现给 CPU ,CPU通过读写这些寄存器和RAM完成对设备的访问和其他操作。按访问方式的不同,x86 架构IO分为 PIO和MMIO
端口IO,即通过IO端口访问设备寄存器。x86有65536个8位的 IO 端口,编号为 0x0-0xFFFF。CPU将端口号作为设备端口的地址,进而对设备进行访问。这 65536 个端口构成了 64KB 的IO端口构成了 64KB 的 IO 端口地址空间。 IO 端口地址空间是独立的,不是线性地址空间或物理地址空间的一部分。需要使用特定的操作命令 IN/OUT 对端口进行访问,此时 CPU 通过一个特殊的管脚标识这是一次 IO 端口访问,于是芯片组知道地址线上的地址是 IO 端口号并相应地完成操作,此外,2个或4个连续的8位IO端口可以组成16位或32位的IO端口。
内存映射IO即通过内存访问的形式访问设备寄存器或设备RAM。MMIO要占用CPU的物理地址空间,它将设备寄存器或设备RAM映射到物理地址空间的某段地址,然后使用 MOV 等访存指令访问此段地址,即可访问到映射的设备。MMIO方式访问设备也需要进行线性地址到物理地址的转换,但是这个转换过程中的 MMIO 地址不可缓存到 TLB 中。MMIO 是一种更普遍、更先进的IO访问方式,很多CPU架构都没有 Port IO,采用统一的 MMIO 方式。
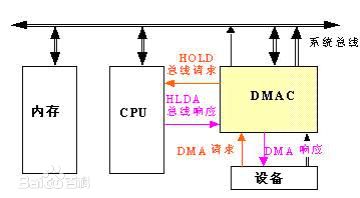
DMA 是所有现代计算机的重要特色。 DMA允许设备绕开 CPU 直接向内存中复制或读取数据。如果设备向内存复制数据都经过 CPU,则CPU会有大量中断负载,中断过程中,CPU对其它任务来讲无法使用,不利于系统性能的提高。通过DMA,CPU只负责初始化这个传输动作,而传输动作本身由DMA控制器(DMAC)来实现和完成。在实现 DMA 传输时,由 DMAC 直接控制总线,在 DMA 传输前,CPU 要把总线控制权交给 DMAC,结束 DMA 传输后,DMAC 立即把总线控制权交回给 CPU。
一个完整的 DMA 传输过程的基本流程如下:
1) DMA 请求:CPU 对 DMAC 进行初始化,并向 IO 端口发出操作命令,IO端口提出 DMA 请求。
2)DMA 响应:DMAC 对 DMA 请求进行优先级判别和屏蔽判别,然后向总线裁决逻辑提出总线请求。CPU执行完当前总线周期后释放总线控制权。此时,总线裁决逻辑发出总线应答,表示 DMA 已被响应 ,并通过 DMAC 通知 IO 端口开始 DMA 传输。
3)DMA 传输:DMAC 获得总线控制权后,CPU即可挂起或只执行内部操作,由 DMAC 发出读写命令,直接控制 RAM 与 IO 端口进行DMA传输。
4)DMA 结束:当完成规定的成批数据传送后,DMAC 释放总线控制权,并向 IO 端口发出结束信号。当IO端口接收到结束信号后,停止 IO 设备的工作并向 CPU 提出中断请求,使 CPU 执行一段检查本次 DMA 传输操作正确性判断的代码,并不介入的状态提出。
由此可见,DMA 无须 CPU 直接控制传输,也没有中断处理方式那样保留现场和恢复现场的过程,通过硬件(DMAC)为 RAM 与 IO 设备开辟了一条直接传送数据的通路,极大地提高了 CPU 效率。需要注意的是,DMA操作访问的必须是连续的物理内存。DMA传输的过程如下图所示。
https://blog.packagecloud.io/eng/2017/02/06/monitoring-tuning-linux-networking-stack-sending-data/ 用DMA模块,其中一个DMA通道1用来装载SPI传输TX数据(触发源为SPI TFFF符号,SPI FIFO可装载),另外一个DMA通道0用来接收SPI数据(触发源为SPI RFDF符号,SPI 接收FIFO非空)。通过使用DMA引擎可以自动发起SPI传输,减少内核在SPI传输过程中的干预,达到降低内核工作负荷的效果。SPI模块采用中断方式。
当有新的数据包来的时候,网卡通过 DMA 将数据写入 RAM (ring buffer), 触发软中断,接着网卡驱动中的 IRQ handler 被调用。 https://blog.packagecloud.io/eng/2016/06/22/monitoring-tuning-linux-networking-stack-receiving-data/#data-arrives
现在的虚拟设备大部分都是采用前后端模型,前文提到的每种资源都可以采用下面的方法进行虚拟化。故应该有9种组合。 我们可以看看下图中实际 qemu 模拟设备。
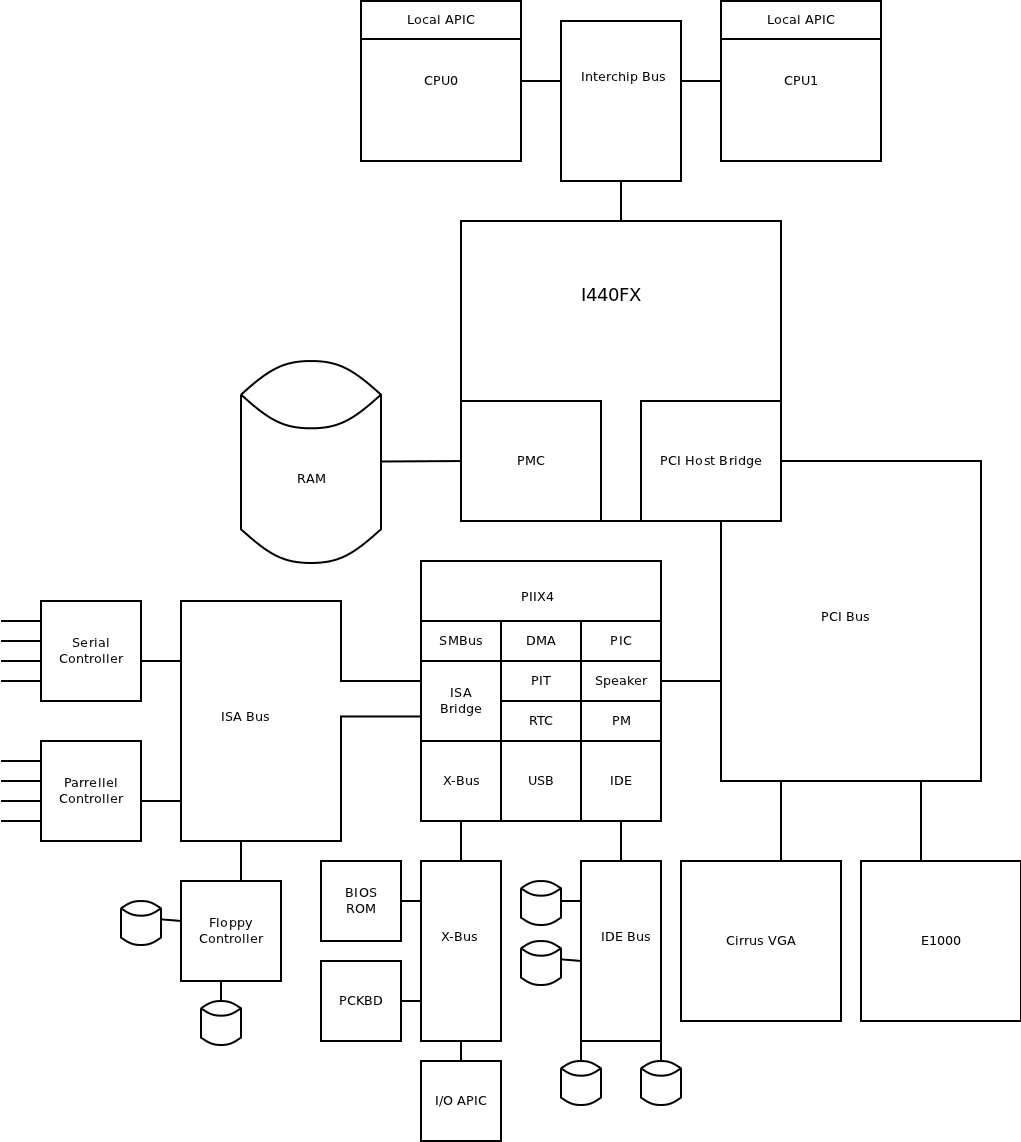
大部分设备需要做是在后端进行模拟,当然复用也主要在后端完成。Host 大部分已经可以实现了(Disk=>File System/Volume; Network=>Socket/Bridge).
有些设备确实不能做多路复用,比如串口,我们可以在 host 段将数据加上 guest 标签,然后客户端开发一个特殊的软件来解析这个特别的串口数据。
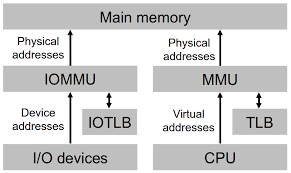
客户机直接操作设备面临如下问题:
问题一可以通过 VT-x 技术解决,而问题二则需要通过 VT-d 的 DMA remapping 解决。IO页表是DMA重映射硬件进行地址转换的核心。它的思想和 CPU中 paging 机制的页表类似,与之不同的是,CPU通过CR3寄存器就可以获得当前系统使用的页表的基地址,而 VT-d 需要借助上一节中介绍根条目和上下文条目才能获得设备对应的 IO 页表。通过 IO页表中 GPA 到 MPA的映射,DMA重映射硬件可以将 DMA 传输中的 GPA 转换成 MPA,从而使设备直接访问指定客户机的内存区域。
legacy service assign/vfio/sriov