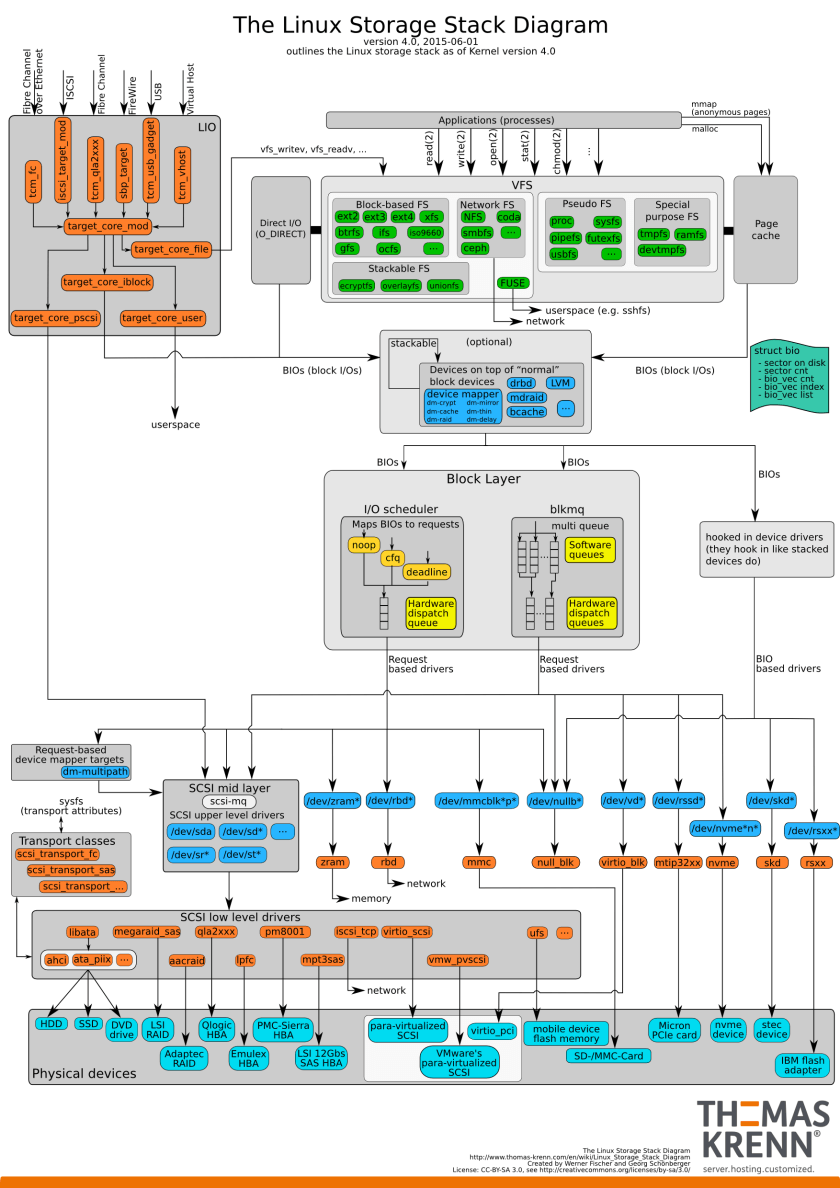
为了支持各种本机文件系统,且在同时允许访问其他操作系统的文件,Linux内核在用户进程(或C标准库)和文件系统实现之间引入了一个抽象层。这个抽象层就是VFS。
基于磁盘的文件系统:所有这些文件系统都使用面向块的介质,必须解决以下问题:如何将文件内容和结构信息存储在目录层次结构上。从文件系统的角度来看,底层块设备无非是存储块组成的一个列表,文件系统相当于对该列表实施一个适当的组织方案。
通用文件模型
VFS 其实采用的面向对象的设计思路,使用一组数据结构来代表通用文件对象。这些数据结构类似于对象。VFS 中有四个主要的对象类型:
超级快对象
各种文件系统都必须实现超级块对象。该对象用于存储特定文件系统的信息,通常对应于存放在磁盘特定扇区中的文件系统超级块或文件系统控制块(所以称为超级块对象给下)。对于并非基于磁盘的文件系统(如基于内存的文件系统,比如sysfs),他们会在使用现场创建超级块并将其保存在内存中。
索引节点对象
索引接点对象包含了内核在操作文件或目录时需要的全部信息。对于UNIX风格的文件系统来说,这些信息可以从磁盘索引节点中直接读入,如果一个文件系统没有索引节点,那么不管这些相关信息在磁盘上是怎么存放的,文件系统都必须从中提取这些信息。没有索引文件系统通常将文件的描述信息作为文件的一部分来存放,这些文件系统和UNIX风格的文件系统不同,没有将数据和控制信息分开存放。有些现代文件系统使用数据库来存储文件的数据。不管哪种情况采用哪种方式,索引节点对象必须在内存中创建,以便于文件系统使用。
目录项对象
VFS把目录当作文件对待,所以在路径/bin/vi中,bin和vi都属于文件,bin是特殊的目录文件和vi是一个普通文件,路径中的每个组成部分都由一个索引节点对象表示。虽然他们可以统一由索引节点表示,但是VFS经常需要执行目录的相关操作,比如路径名查询等。路径名查询需要解析路径中的每一个组成部分,不但要确保它有效,而且需要进一步寻找路径中的下一个部分。
为了方便查找操作,VFS引入了目录项的概念,每个 dentry 代表路径中的一个特定部分,对于前一个例子来说,/、bin和vi都属于目录项对象,前两个是目录,最后一个是普通文件,必须明确一点,在路径中(包括普通文件在内),每一个部分都是目录项对象。解析一个路径并遍历其分量绝非简单的的演练,它是耗时的、常规的字符串比较操作,执行耗时,代码繁琐。目录项对象的引入使得这个过程更加简单,目录项上也包括安装点。目录项也可包括安装点。在路径 /mnt/cdrom/foo 中,构成元素 /、mnt、cdrom 和 foo都属于目录项对象。VFS在执行目录操作时(如果需要的话)会现场创建目录项对象。
文件对象
VFS的最后一个主要对象是文件对象。文件对象表示进程已打开的文件,如果我们站在用户角度来看待VFS。文件对象会首先进入我们的视野,进程直接处理的是文件,而不是超级快、索引接点和目录项。所以不必奇怪:文件对象包含我们非常熟悉的信息(如访问模式、当前偏移等),同样道理,文件操作和我们非常熟悉的系统调用 read 和 write 等也很类似。
文件对象是已打开的文件在内存中的表示。该对象(不是物理文件)由相应的 open 系统调用创建,有close系统调用撤销,所有这些文件相关的调用实际上都是文件操作表中定义的方法。因为多个进程可以同时打开和操作同一个文件,所以同一个文件也可能存在多个对应的文件对象。文件对象仅仅在进程观点上代表已打开文件,它反过来指向目录项对象(反过来指向索引节点),其实只有目录项对象才表示已打开的实际文件。虽然一个文件对应的文件对象不是唯一的,但对应的索引节点和目录项无疑是唯一的。
有时候需要在Linuxkernel–大多是在需要调试的驱动程序–中读写文件数据。在kernel中操作文件没有标准库可用,需要利用kernel的一些函数,这些函数主 要有: filp_open() filp_close(), vfs_read() vfs_write(),set_fs(),get_fs()等,这些函数在linux/fs.h和asm/uaccess.h头文件中声明。下面介绍主要步骤
打开文件
filp_open()在kernel中可以打开文件,该函数返回strcut file*结构指针,供后继函数操作使用,该返回值用IS_ERR()来检验其有效性
strcut file* filp_open(const char* filename, int open_mode, int mode);
参数说明:
filename: 表明要打开或创建文件的名称(包括路径部分)。在内核中打开的文件时需要注意打开的时机,很容易出现需要打开文件的驱动很早就加载并打开文件,但需要打开的文件所在设备还不有挂载到文件系统中,而导致打开失败。
open_mode: 文件的打开方式,其取值与标准库中的open相应参数类似,可以取O_CREAT,O_RDWR,O_RDONLY等。
mode: 创建文件时使用,设置创建文件的读写权限,其它情况可以匆略设为0
读写文件
kernel中文件的读写操作可以使用vfs_read()和vfs_write,在使用这两个函数前需要说明一下get_fs()和 set_fs()这两个函数。 vfs_read() vfs_write()两函数的原形如下:
ssize_t vfs_read(struct file* filp, char __user* buffer, size_t len, loff_t* pos);
ssize_t vfs_write(struct file* filp, const char __user* buffer, size_t len, loff_t* pos);
注意这两个函数的第二个参数buffer,前面都有__user修饰符,这就要求这两个buffer指针都应该指向用空的内存,如果对该参数传递kernel空间的指针,这两个函数都会返回失败-EFAULT。但在Kernel中,我们一般不容易生成用户空间的指针,或者不方便独立使用用户空间内存。要使这两个读写函数使用kernel空间的buffer指针也能正确工作,需要使用set_fs()函数或宏(set_fs()可能是宏定义),如果为函数,其原形如下:
void set_fs(mm_segment_t fs);
该函数的作用是改变kernel对内存地址检查的处理方式,其实该函数的参数fs只有两个取值:USER_DS,KERNEL_DS,分别代表 用户空间和内核空间,默认情况下,kernel取值为USER_DS,即对用户空间地址检查并做变换。那么要在这种对内存地址做检查变换的函数中使用内核 空间地址,就需要使用set_fs(KERNEL_DS)进行设置。get_fs()一般也可能是宏定义,它的作用是取得当前的设置,这两个函数的一般用 法为: mm_segment_t old_fs; old_fs = get_fs(); set_fs(KERNEL_DS); …… //与内存有关的操作
set_fs(old_fs);
还有一些其它的内核函数也有用__user修饰的参数,在kernel中需要用kernel空间的内存代替时,都可以使用类似办法。 使用vfs_read()和vfs_write()最后需要注意的一点是最后的参数loff_t * pos,pos所指向的值要初始化,表明从文件的什么地方开始读写。
关闭文件 int filp_close(struct file*filp, fl_owner_t id); 该函数的使用很简单,第二个参数一般传递NULL值,也有用current->files作为实参的。 使用以上函数的其它注意点:
只要文件系统跑起来之后内核空间就可以像在用户空间一样操作文件.
用户空间 内核
open() sys_open(), filp_open()
close() sys_close(), filp_close()
read() sys_read(), filp_read()
write() sys_write(), filp_write()
在内核模块中有时会用不了 sys_xxxx, 这时用 filp_xxxx 对应的函数就行了.
在 /tmp 中创建文件 aa
struct file *filep;
filep=filp_open("/tmp/aa",O_CREAT | O_RDWR,0);
if(IS_ERR(filep))
return -1;
filp_close(filep,0);
return 0;
文件操作例子
见附录一
I/O 调度算法在各个进程竞争磁盘I/O的时候担当了裁判的角色。他要求请求的次序和时机做最优化的处理,以求得尽可能最好的整体I/O性能。
I/O调度程序的总结:
从原理上看:
cfq:是一种比较通用的调度算法,是一种以进程为出发点考虑的调度算法,保证大家尽量公平。
deadline: 是一种以提高机械硬盘吞吐量为思考出发点的调度算法,只有当有io请求达到最终期限的时候才进行调度,非常适合业务比较单一并且IO压力比较重的业务,比如数据库。
noop: 思考对象如果拓展到固态硬盘,那么你就会发现,无论cfq还是deadline,都是针对机械硬盘的结构进行的队列算法调整,而这种调整对于固态硬盘来说,完全没有意义。对于固态硬盘来说,IO调度算法越复杂,效率就越低,因为额外要处理的逻辑越多。所以,固态硬盘这种场景下,使用noop是最好的,deadline次之,而cfq由于复杂度的原因,无疑效率最低。
CFQ(完全公平排队I/O调度程序)
在最新的内核版本和发行版中,都选择CFQ做为默认的I/O调度器,对于通用的服务器也是最好的选择。CFQ对于多媒体应用(video,audio)和桌面系统是最好的选择。CFQ赋予I/O请求一个优先级,而I/O优先级请求独立于进程优先级,高优先级的进程的读写不能自动地继承高的I/O优先级。对于很多IO压力较大的场景就并不是很适应,尤其是IO压力集中在某些进程上的场景。因为这种场景我们需要更多的满足某个或者某几个进程的IO响应速度,而不是让所有的进程公平的使用IO,比如数据库应用。CFQ试图均匀地分布对I/O带宽的访问,避免进程被饿死并实现较低的延迟,是deadline和as调度器的折中.
工作原理: CFQ为每个进程/线程,单独创建一个队列来管理该进程所产生的请求,也就是说每个进程一个队列,每个队列按照上述规则进行merge和sort。各队列之间的调度使用时间片来调度,以此来保证每个进程都能被很好的分配到I/O带宽.I/O调度器每次执行一个进程的4次请求。可以调 queued 和 quantum 来优化
NOOP(电梯式调度程序)
在Linux2.4或更早的版本的调度程序,那时只有这一种I/O调度算法.I/O请求被分配到队列,调度由硬件进行,只有当CPU时钟频率比较有限时进行。
Noop对于I/O不那么操心,对所有的I/O请求都用FIFO队列形式处理,默认认为 I/O不会存在性能问题。这也使得CPU也不用那么操心。它像电梯的工作主法一样对I/O请求进行组织,当有一个新的请求到来时,它将请求合并到最近的请求之后,以此来保证请求同一介质.
NOOP倾向饿死读而利于写. NOOP对于闪存设备,RAM,嵌入式系统是最好的选择.
电梯算法饿死读请求的解释: 因为写请求比读请求更容易. 写请求通过文件系统cache,不需要等一次写完成,就可以开始下一次写操作,写请求通过合并,堆积到I/O队列中. 读请求需要等到它前面所有的读操作完成,才能进行下一次读操作.在读操作之间有几毫秒时间,而写请求在这之间就到来,饿死了后面的读请求.
Deadline(截止时间调度程序)
通过时间以及硬盘区域进行分类,这个分类和合并要求类似于noop的调度程序. Deadline确保了在一个截止时间内服务请求,这个截止时间是可调整的,而默认读期限短于写期限.这样就防止了写操作因为不能被读取而饿死的现象. Deadline对数据库环境(ORACLE RAC,MYSQL等)是最好的选择。
deadline实现了四个队列,其中两个分别处理正常read和write,按扇区号排序,进行正常io的合并处理以提高吞吐量.因为IO请求可能会集中在某些磁盘位置,这样会导致新来的请求一直被合并,于是可能会有其他磁盘位置的io请求被饿死。于是实现了另外两个处理超时read和write的队列,按请求创建时间排序,如果有超时的请求出现,就放进这两个队列,调度算法保证超时(达到最终期限时间)的队列中的请求会优先被处理,防止请求被饿死。由于deadline的特点,无疑在这里无法区分进程,也就不能实现针对进程的io资源控制。
AS(预料I/O调度程序) 本质上与Deadline一样,但在最后一次读操作后,要等待6ms,才能继续进行对其它I/O请求进行调度.可以从应用程序中预订一个新的读请求,改进读操作的执行,但以一些写操作为代价.它会在每个6ms中插入新的I/O操作,而会将一些小写入流合并成一个大写入流,用写入延时换取最大的写入吞吐量. AS适合于写入较多的环境,比如文件服务器 AS对数据库环境表现很差.
查看当前系统的I/O调度方法:
$ cat /sys/block/sda/queue/scheduler
noop anticipatory deadline [cfq]
临地更改I/O调度方法:
例如:想更改到noop电梯调度算法:
$ echo noop > /sys/block/sda/queue/scheduler
想永久的更改I/O调度方法:
修改内核引导参数,加入elevator=调度程序名
$ vi /boot/grub/menu.lst
更改到如下内容:
kernel /boot/vmlinuz-2.6.18-8.el5 ro root=LABEL=/ elevator=deadline rhgb quiet
重启之后,查看调度方法:
$ cat /sys/block/sda/queue/scheduler
noop anticipatory [deadline] cfq
在阅读Linux2.6的内核内存管理这一部分时,我看到page结构中的一个mapping成员,我感到很迷惑,这个成员的属性太复杂了,我们来看看: struct address_space *mapping;表示该页所在地址空间描述结构指针,用于内容为文件的页帧。
看linux内核很容易被struct address_space 这个结构迷惑,它是代表某个地址空间吗?实际上不是的,它是用于管理文件(struct inode)映射到内存的页面(struct page)的;与之对应,address_space_operations 就是用来操作该文件映射到内存的页面,比如把内存中的修改写回文件、从文件中读入数据到页面缓冲等。也就是说address_space结构与文件的对应:一个具体的文件在打开后,内核会在内存中为之建立一个struct inode结构,其中的i_mapping域指向一个address_space结构。这样,一个文件就对应一个address_space结构,一个 address_space与一个偏移量能够确定一个page cache 或swap cache中的一个页面。因此,当要寻址某个数据时,很容易根据给定的文件及数据在文件内的偏移量而找到相应的页面。
下面先看下address_space结构定义:
struct address_space {
struct inode *host; /* owner: inode, block_device拥有它的节点 */
struct radix_tree_root page_tree; /* radix tree of all pages包含全部页面的radix树 */
rwlock_t tree_lock; /* and rwlock protecting it保护page_tree的自旋锁 */
unsigned int i_mmap_writable;/* count VM_SHARED mappings共享映射数VM_SHARED记数*/
struct prio_tree_root i_mmap; /* tree of private and shared mappings 优先搜索树的树根*/
struct list_head i_mmap_nonlinear;/*list VM_NONLINEAR mappings 非线性映射的链表头*/
spinlock_t i_mmap_lock; /* protect tree, count, list 保护i_mmap的自旋锁*/
unsigned int truncate_count; /* Cover race condition with truncate 将文件截断的记数*/
unsigned long nrpages; /* number of total pages 页总数*/
pgoff_t writeback_index;/* writeback starts here 回写的起始偏移*/
struct address_space_operations *a_ops; /* methods 操作函数表*/
unsigned long flags; /* error bits/gfp mask ,gfp_mask掩码与错误标识 */
struct backing_dev_info *backing_dev_info; /* device readahead, etc预读信息 */
spinlock_t private_lock; /* for use by the address_space 私有address_space锁*/
struct list_head private_list; /* ditto 私有address_space链表*/
struct address_space *assoc_mapping; /* ditto 相关的缓冲*/
} __attribute__((aligned(sizeof(long))));
了解了 address_space 之后,我们就知道“一个 address_space与一个偏移量能够确定一个page cache 或swap cache中的一个页面”
page cache是与文件映射对应的,而swap cache是与匿名页对应的。如果一个内存页面不是文件映射,则在换入换出的时候加入到swap cache,如果是文件映射,则不需要交换缓冲。 原来这两个相同的就是都是address_space,都有相对应的文件操作。:一个被访问文件的物理页面都驻留在page cache或swap cache中,一个页面的所有信息由struct page来描述。struct page中有一个域为指针mapping ,它指向一个struct address_space类型结构。page cache或swap cache中的所有页面就是根据address_space结构以及一个偏移量来区分的。而在这里我可以负责任的告诉大家这个偏移量就是进程线性空间中某个线性地址对应的二级描述符(注意:我这里说的是以SEP4020这个arm结构为例的,它只有二级映射,另外这个二级描述符也是Linux版的,而不是硬件版的描述符)。
一般情况下用户进程调用mmap()时,只是在进程空间内新增了一块相应大小的缓冲区,并设置了相应的访问标识,但并没有建立进程空间到物理页面的映射。因此,第一次访问该空间时,会引发一个缺页异常。、对于共享内存映射情况,缺页异常处理程序首先在swap cache中寻找目标页(符合address_space以及偏移量的物理页),如果找到,则直接返回地址;如果没有找到,则判断该页是否在交换区 (swap area),如果在,则执行一个换入操作;如果上述两种情况都不满足,处理程序将分配新的物理页面,并把它插入到page cache中。进程最终将更新进程页表。注:对于映射普通文件情况(非共享映射),缺页异常处理程序首先会在page cache中根据address_space以及数据偏移量寻找相应的页面。如果没有找到,则说明文件数据还没有读入内存,处理程序会从磁盘读入相应的页面,并返回相应地址,同时,进程页表也会更新。
当将页面交换到交换文件中时,Linux总是避免页面写,除非必须这样做。当页面已经被交换出内存但是当有进程再次访问时又要将它重新调入内存。只要页面在内存中没有被写过,则交换文件中的拷贝是有效的。
Linux使用swap cache来跟踪这些页面。这个swap cache是一个页表入口链表,每个对应于系统中的物理页面。这是一个对应于交换出页面的页表入口并且描叙页面放置在哪个交换文件中以及在交换文件中的位置。如果swap cache入口为非0值,则表示在交换文件中的这一页没有被修改。如果此页被修改(或者写入)。 则其入口从swap cache中删除。
当Linux需要将一个物理页面交换到交换文件时,它将检查swap cache,如果对应此页面存在有效入口,则不必将这个页面写到交换文件中。这是因为自从上次从交换文件中将其读出来,内存中的这个页面还没有被修改。
swap cache中的入口是已换出页面的页表入口。它们虽被标记为无效但是为Linux提供了页面在哪个交换文件中以及文件中的位置等信息。 保存在交换文件中的dirty页 面可能被再次使用到,例如,当应用程序向包含在已交换出物理页面上的虚拟内存区域写入时。对不在物理内存中的虚拟内存页面的访问将引发页面错误。由于处理 器不能将此虚拟地址转换成物理地址,处理器将通知操作系统。由于已被交换出去,此时描叙此页面的页表入口被标记成无效。处理器不能处理这种虚拟地址到物理 地址的转换,所以它将控制传递给操作系统,同时通知操作系统页面错误的地址与原因。这些信息的格式以及处理器如何将控制传递给操作系统与具体硬件有关。
处理器相关页面错误处理代码将定位描叙包含出错虚拟地址对应的虚拟内存区域的vm_area_struct数据结构。它通过在此进程的vm_area_struct中查找包含出错虚拟地址的位置直到找到为止。这些代码与时间关系重大,进程的vm_area_struct数据结构特意安排成使查找操作时间更少。 执行完这些处理器相关操作并且找到出错虚拟地址的有效内存区域后,页面错处理过程其余部分和前面类似。 通用页面错处理代码为出错虚拟地址寻找页表入口。如果找到的页表入口是一个已换出页面,Linux必须将其交换进入物理内存。已换出页面的页表入口的格式与处理器类型有关,但是所有的处理器将这些页面标记成无效并把定位此页面的必要信息放入页表入口中。Linux利用这些信息以便将页面交换进物理入内存。
此时Linux知道出错虚拟内存地址并且拥有一个包含页面位置信息的页表入口。vm_area_struct数据结构可能包含将此虚拟内存区域交换到物理内存中的子程序:swapin。如果对此虚拟内存区域存在swapin则Linux会使用它。这是已换出系统V共享内存页面的处理过程-因为已换出系统V共享页面和普通的已换出页面有少许不同。如果没有swapin操作,这可能是Linux假定普通页面无须特殊处理。 系统将分配物理页面并将已换出页面读入。关于页面在交换文件中位置信息从页表入口中取出。如果引起页面错误的访问不是写操作则页面被保留在swap cache中并且它的页表入口不再标记为可写。如果页面随后被写入,则将产生另一个页面错误,这时页面被标记为dirty,同时其入口从swap cache中删除。如果页面没有被写并且被要求重新换出,Linux可以免除这次写,因为页面已经存在于交换文件中。 如果引起页面从交换文件中读出的操作是写操作,这个页面将被从swap cache中删除并且其页表入口被标记成dirty且可写。
说到page cache我们很容易就与buffer cache混淆,在这里我需要说的是page cache是VFS的一部分,buffer cache是块设备驱动的一部分,或者说page cache是面向用户IO的cache,buffer cache是面向块设备IO的cache,page cache按照文件的逻辑页进行缓冲,buffer cache按照文件的物理块进行缓冲。page cache与buffer cache并不相互独立而是相互融合的,同一文件的cache页即可存在于page cache中,又可存在于buffer cache中,它们在物理内存中只有一份拷贝。文件系统接口就处于page cache和buffer cache之间,它完成page cache的逻辑页与buffer cache的物理块之间的相互转换,再交给统一的块设备IO进行调度处理,文件的逻辑块与物理块的关系就表现为page cache与buffer cache的关系。
Page cache实际上是针对文件系统的,是文件的缓存,在文件层面上的数据会缓存到page cache。文件的逻辑层需要映射到实际的物理磁盘,这种映射关系由文件系统来完成。当page cache的数据需要刷新时,page cache中的数据交给buffer cache,但是这种处理在2.6版本的内核之后就变的很简单了,没有真正意义上的cache操作。
Buffer cache是针对磁盘块的缓存,也就是在没有文件系统的情况下,直接对磁盘进行操作的数据会缓存到buffer cache中,例如,文件系统的元数据都会缓存到buffer cache中。
简单说来,page cache用来缓存文件数据,buffer cache用来缓存磁盘数据。在有文件系统的情况下,对文件操作,那么数据会缓存到page cache,如果直接采用dd等工具对磁盘进行读写,那么数据会缓存到buffer cache。
可以参看 kernel driver 这篇文章
read()
VFS(虚拟文件系统)
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
........
ret = vfs_read(file, buf, count, &pos);
........
}
-->vfs_read-->(ext2_file_operation)do_sync_read
Ext2文件系统层的处理, 通过ext2_file_operations结构知道,上述函数最终会调用到do_sync_read函数,它是系统通用的读取函数。所以说,do_sync_read才是ext2层的真实入口。该层入口函数 do_sync_read 调用函数 generic_file_aio_read,进入page caches
generic_file_aio_read 后者判断本次读请求的访问方式。 –> 如果是直接 io (filp->f_flags 被设置了 O_DIRECT 标志,即不经过 cache)的方式,则调用 generic_file_direct_IO 函数; –> 如果是 page cache 的方式,则调用 do_generic_file_read 函数。
// 这里 mapping(address_space指针)是指定的地址空间,index是文件中的指定的位置,以页面为单位。
page = find_get_page(mapping, index);
if (!page) {
page_cache_sync_readahead(mapping, ra, filp, index, last_index - index);
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page;
}
它会判断该页是否在页高速缓存,如果是,直接将数据拷贝到用户空间。
如果不在,则调用page_cache_sync_readahead函数执行预读(检查是否可以预读),它会调用mpage_readpages。如果仍然未能命中(可能不允许预读或者其它原因),则直接跳转readpage,执行mpage_readpage,从磁盘读取数据。
预读: 是指文件系统为应用程序一次读出比预期更多的文件内容并缓存在page cache中,这样下一次读请求到来时部分页面直接从page cache读取即可。当然,这个细节对应用程序透明,应用程序可能的感觉唯一就是下次读的速度会更快,当然这是好事。
在mpage_readpages(一次读多个页)中,它会将连续的磁盘块放入同一个BIO,并延缓BIO的提交,直到出现不连续的块,则直接提交BIO,再继续处理,以构造另外的BIO。
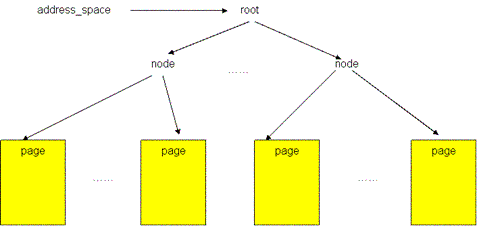
上图显示了一个文件的 page cache 结构。文件被分割为一个个以 page 大小为单元的数据块,这些数据块(页)被组织成一个多叉树(称为 radix 树)。树中所有叶子节点为一个个页帧结构(struct page),表示了用于缓存该文件的每一个页。在叶子层最左端的第一个页保存着该文件的前4096个字节(如果页的大小为4096字节),接下来的页保存着文件第二个4096个字节,依次类推。树中的所有中间节点为组织节点,指示某一地址上的数据所在的页。此树的层次可以从0层到6层,所支持的文件大小从0字节到16 T 个字节。树的根节点指针可以从和文件相关的 address_space 对象(该对象保存在和文件关联的 inode 对象中)中取得(更多关于 page cache 的结构内容请参见参考资料)。 mpage处理机制就是page cache层要处理的问题。
在缓存层处理末尾,执行mpage_submit_bio之后,会调用generic_make_request函数。这是通用块层的入口函数。它将bio传送到IO调度层进行处理。__make_request
对bio进行合并、排序,以提高IO效率。然后,调用设备驱动层的回调函数,request_fn(scsi_request_fn),转到设备驱动层处理。 elv_merge(struct request_queue *q, struct request **req, struct bio *bio)
request函数对请求队列中每个bio进行分别处理,根据bio中的信息向磁盘控制器发送命令。处理完成后,调用完成函数end_bio以通知上层完成。
sys_open 的使用方法:
#include <linux/fs.h>
......
u8 Buff[50];
int fd;
memset(Buff, 0x00, sizeof(Buff));
mm_segment_t old_fs = get_fs();
set_fs(KERNEL_DS);
fd = sys_open("/etc/Info", O_RDONLY, 0);
if(fd>=0)
{
sys_read(fd, Buff, 50);
printk("string: %s/n", Buff);
sys_close(fd);
}
set_fs(old_fs);
下面 open 使用的一些参数:
O_ACCMODE <0003>;: 读写文件操作时,用于取出flag的低2位。
O_RDONLY<00>;: 只读打开
O_WRONLY<01>;: 只写打开
O_RDWR<02>;: 读写打开
O_CREAT<0100>;: 文件不存在则创建,需要mode_t,not fcntl
O_EXCL<0200>;: 如果同时指定了O_CREAT,而文件已经存在,则出错, not fcntl
O_NOCTTY<0400>;: 如果pathname指终端设备,则不将此设备分配作为此进程的控制终端。not fcntl O_TRUNC<01000>;: 如果此文件存在,而且为只读或只写成功打开,则将其长度截短为0。not fcntl
O_APPEND<02000>;: 每次写时都加到文件的尾端
O_NONBLOCK<04000>;: 如果p a t h n a m e指的是一个F I F O、一个块特殊文件或一个字符特殊文件,则此选择项为此文件的本次打开操作和后续的I / O操作设置非阻塞方式。
O_NDELAY;;
O_SYNC<010000>;: 使每次write都等到物理I/O操作完成。
FASYNC<020000>;: 兼容BSD的fcntl同步操作
O_DIRECT<040000>;: 直接磁盘操作标识
O_LARGEFILE<0100000>;: 大文件标识
O_DIRECTORY<0200000>;: 必须是目录
O_NOFOLLOW<0400000>;: 不获取连接文件
O_NOATIME<01000000>;: 暂无
当新创建一个文件时,需要指定mode 参数,以下说明的格式如宏定义名称<实际常数值>;: 描述。
S_IRWXU<00700>;:文件拥有者有读写执行权限
S_IRUSR (S_IREAD)<00400>;:文件拥有者仅有读权限
S_IWUSR (S_IWRITE)<00200>;:文件拥有者仅有写权限
S_IXUSR (S_IEXEC)<00100>;:文件拥有者仅有执行权限
S_IRWXG<00070>;:组用户有读写执行权限
S_IRGRP<00040>;:组用户仅有读权限
S_IWGRP<00020>;:组用户仅有写权限
S_IXGRP<00010>;:组用户仅有执行权限
S_IRWXO<00007>;:其他用户有读写执行权限
S_IROTH<00004>;:其他用户仅有读权限
S_IWOTH<00002>;:其他用户仅有写权限
S_IXOTH<00001>;:其他用户仅有执行权限
Linux驱动编程书籍大多数都是介绍怎样用户态下怎么访问硬件设备,由于项目的需要,本人做了内核态下访问设备文件的方法,现在把程序拿出来和大家分享一下,希望对刚入门的朋友有所帮助。 在我的《内核模块调用驱动》中给出了简单的字符设备文件程序,可以作为本文的驱动对象,在此,我就不多介绍了。调用驱动程序的模块如下:
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/stat.h>
#include <linux/fs.h>
#include <asm/unistd.h>
#include <asm/uaccess.h>
#include <linux/types.h>
#include <linux/ioctl.h>
#include "chardev.h"
MODULE_LICENSE("GPL");
//#define __KERNEL_SYSCALLS__
#define bao "/dev/baovar"
static char buf1[20];
static char buf2[20];
static int __init testmod_init(void)
{
mm_segment_t old_fs;
ssize_t result;
ssize_t ret;
sprintf(buf1,"%s","baoqunmin");
struct file *file=NULL;
file=filp_open(bao,O_RDWR,0);
if(IS_ERR(file)) goto fail0;
old_fs=get_fs();
set_fs(get_ds());
ret=file->f_op->write(file,buf1,sizeof(buf1),&file->f_pos);
result=file->f_op->read(file,buf2,sizeof(buf2),&file->f_pos);
if(result>=0){buf2[20]='/n';
printk("buf2-->%s/n",buf2);}
else
printk("failed/n");
result=file->f_op->ioctl(file,buf2,sizeof(buf2),&file->f_pos);
result=file->f_op->read(file,buf2,sizeof(buf2),&file->f_pos);
set_fs(old_fs);
filp_close(file,NULL);
printk("file loaded/n");
return 0;
fail0:
{
filp_close(file,NULL);
printk("load failed/n");
}
return 1;
}
static void __exit testmod_cleanup(void)
{
printk("module exit....................................................../n");
}
module_init(testmod_init);
module_exit(testmod_cleanup);
以上是完整的程序,直接可以编译运行。
#include "chardev.h"头文件定义如下,此头文件也必须在驱动中包含!
#include <linux/ioctl.h>
#define BAO_IOCTL 't'
#define IOCTL_READ _IOR(BAO_IOCTL, 0, int)
#define IOCTL_WRITE _IOW(BAO_IOCTL, 1, int)
#define BAO_IOCTL_MAXNR 1
以下给出了我的Makefile文件:
CC=gcc
MODCFLAGS := -Wall -DMODULE -D__KERNEL__ -DLINUX -I/usr/src/linux-2.4.20-8/include
test.o :test.c
$(CC) $(MODCFLAGS) -c test.c
echo insmod test.o to turn it on
echo rmmod test to turn it off
echo
Linux IO 调度分析
http://www.360doc.com/content/12/0201/22/2459_183505470.shtml
Read 系统调用解析
https://www.ibm.com/developerworks/cn/linux/l-cn-read/
Linux AIO
https://www.ibm.com/developerworks/cn/linux/l-async/
文件系统预读
http://blog.csdn.net/kai_ding/article/details/17322787
http://os.51cto.com/art/200910/159067_all.htm
磁盘IO调度算法 http://www.cnblogs.com/kongzhongqijing/articles/5786002.html