ip_local_output–>ip_output–>ip_finish_output–>ip_finish_output2–>neigh_output–>neigh_bh_output–>dev_queue_xmit–>sch_direct_xmit–>dev_hard_start_xmit(net_device_ops的注册)–>higmac_net_hard_start_xmit
netstat -nr 命令可显示路由表的内容
| TCP UDP
---------------------------------------------------------------------
应用层 | 流 报文
传输层 | 段 分组
网间层 | 数据报 数据报
网络访问层 | 帧 帧
---------------------------------------------------------------------
select select最早于1983年出现在4.2BSD中,它通过一个select()系统调用来监视多个文件描述符的数组,当select()返回后,该数组中就绪的文件描述符便会被内核修改标志位,使得进程可以获得这些文件描述符从而进行后续的读写操作。select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点,事实上从现在看来,这也是它所剩不多的优点之一。
select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,不过可以通过修改宏定义甚至重新编译内核的方式提升这一限制。另外,select()所维护的存储大量文件描述符的数据结构,随着文件描述符数量的增大,其复制的开销也线性增长。同时,由于网络响应时间的延迟使得大量TCP连接处于非活跃状态,但调用select()会对所有socket进行一次线性扫描,所以这也浪费了一定的开销。
poll poll在1986年诞生于System V Release 3,它和select在本质上没有多大差别,但是poll没有最大文件描述符数量的限制。poll和select同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
另外,select()和poll()将就绪的文件描述符告诉进程后,如果进程没有对其进行IO操作,那么下次调用select()和poll()的时候将再次报告这些文件描述符,所以它们一般不会丢失就绪的消息,这种方式称为水平触发(Level Triggered)。
epoll 直到Linux2.6才出现了由内核直接支持的实现方法,那就是epoll,它几乎具备了之前所说的一切优点,被公认为Linux2.6下性能最好的多路I/O就绪通知方法。epoll可以同时支持水平触发和边缘触发(Edge Triggered,只告诉进程哪些文件描述符刚刚变为就绪状态,它只说一遍,如果我们没有采取行动,那么它将不会再次告知,这种方式称为边缘触发),理论上边缘触发的性能要更高一些,但是代码实现相当复杂。
epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在系统调用时复制的开销。
另一个本质的改进在于epoll采用基于事件的就绪通知方式。在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
具体使用和实例参考下面的网站
http://www.cnblogs.com/coser/archive/2012/01/06/2315216.html
poll_wait()是用在select系统调用中的.
一般你的代码会有一个struct file_operations结构, 其中fop->poll函数指针指向一个你自己的函数, 在这个函数里应该调用poll_wait()
当用户调用select系统调用时,select系统调用会 先调用 poll_initwait(&table); 然后调用你的 fop->poll(); 从而将current加到某个等待队列(这里调用poll_wait()), 并检查是否有效 如果无效就调用 schedule_timeout(); 去睡眠.
事件发生后,schedule_timeout()回来,调用 fop->poll(); 检查到可以运行,就调用 poll_freewait(&table);
从而完成select系统调用.
首先再来提一下I/O多路转接的基本思想:先构造一张有关描述符的表,然后调用一个函数,它要到这些描述符中的一个已准备好进行 I/O时才返回。在返回时,它告诉进程哪一个描述符已准备好可以进行 I/O。
select函数的参数将告诉内核:
select从内核返回后内核会告诉我们:
select 用于查询设备的状态,以便用户程序获知是否能对设备进行非阻塞的访问,需要设备驱动程序中的poll 函数支持。 驱动程序中 poll 函数中最主要用到的一个 API 是 poll_wait,其原型如下:
void poll_wait(struct file *filp, wait_queue_heat_t *queue, poll_table * wait);
poll_wait 函数所做的工作是把当前进程添加到 wait 参数指定的等待列表(poll_table)中。 需要说明的是,poll_wait 函数并不阻塞,程序中 poll_wait(filp, &outq, wait)这句话的意思并不是说一直等待 outq 信号量可获得,真正的阻塞动作是上层的 select/poll 函数中完成的。select/poll 会在一个循环中对每个需要监听的设备调用它们自己的 poll 支持函数以使得当前进程被加入各个设备的等待列表。若当前没有任何被监听的设备就绪,则内核进行调度(调用 schedule)让出 cpu 进入阻塞状态,schedule 返回时将再次循环检测是否有操作可以进行,如此反复;否则,若有任意一个设备就绪,select/poll 都立即返回。
应用程序调用select() 函数,系统调用陷入内核,进入到:
SYSCALL_DEFINE5 (sys_select)----> core_sys_select -----> do_select()
SYSCALL_DEFINE5(select, int, n, fd_set __user *, inp, fd_set __user *, outp,
fd_set __user *, exp, struct timeval __user *, tvp)//n为文件描述符{ struct timespec end_time, *to = NULL; struct timeval tv; int ret;
if (tvp) { if (copy_from_user(&tv, tvp, sizeof(tv))) return -EFAULT;
to = &end_time; if (poll_select_set_timeout(to,
tv.tv_sec + (tv.tv_usec / USEC_PER_SEC),
(tv.tv_usec % USEC_PER_SEC) * NSEC_PER_USEC)) return -EINVAL;
}
ret = core_sys_select(n, inp, outp, exp, to);
ret = poll_select_copy_remaining(&end_time, tvp, 1, ret);
return ret;
}
在core_sys_select() 函数中调用了do_select:
int do_select(int n, fd_set_bits *fds, struct timespec *end_time)
{
ktime_t expire, *to = NULL;
struct poll_wqueues table;
poll_table *wait;
int retval, i, timed_out = 0;
unsigned long slack = 0;
rcu_read_lock();
retval = max_select_fd(n, fds);
rcu_read_unlock();
if (retval < 0)
return retval;
n = retval;
poll_initwait(&table);//初始化结构体,主要是初始化poll_wait的回调函数为__pollwait
wait = &table.pt;
if (end_time && !end_time->tv_sec && !end_time->tv_nsec) {
wait = NULL;
timed_out = 1;
}
if (end_time && !timed_out)
slack = estimate_accuracy(end_time);
retval = 0;
for (;;) {
unsigned long *rinp, *routp, *rexp, *inp, *outp, *exp;
inp = fds->in; outp = fds->out; exp = fds->ex;
rinp = fds->res_in; routp = fds->res_out; rexp = fds->res_ex;
for (i = 0; i < n; ++rinp, ++routp, ++rexp) {
unsigned long in, out, ex, all_bits, bit = 1, mask, j;
unsigned long res_in = 0, res_out = 0, res_ex = 0;
const struct file_operations *f_op = NULL;
struct file *file = NULL;
in = *inp++; out = *outp++; ex = *exp++;
all_bits = in | out | ex;
if (all_bits == 0) {
i += __NFDBITS;
continue;
}
for (j = 0; j < __NFDBITS; ++j, ++i, bit <<= 1) {
int fput_needed;
if (i >= n)
break;
if (!(bit & all_bits))
continue;
file = fget_light(i, &fput_needed);
if (file) {
f_op = file->f_op;
mask = DEFAULT_POLLMASK;
if (f_op && f_op->poll) {
wait_key_set(wait, in, out, bit);
mask = (*f_op->poll)(file, wait););//调用poll_wait处理过程,
//即把驱动中等待队列头增加到poll_wqueues中的entry中,并把指向
//当前里程的等待队列项增加到等待队列头中。每一个等待队列头占用一个entry
}
fput_light(file, fput_needed);
if ((mask & POLLIN_SET) && (in & bit)) {//如果有信号进行设置,记录,写回到对应项,设置跳出循环的retval
res_in |= bit;
retval++;
wait = NULL;
}
if ((mask & POLLOUT_SET) && (out & bit)) {
res_out |= bit;
retval++;
wait = NULL;
}
if ((mask & POLLEX_SET) && (ex & bit)) {
res_ex |= bit;
retval++;
wait = NULL;
}
}
}
if (res_in)
*rinp = res_in;
if (res_out)
*routp = res_out;
if (res_ex)
*rexp = res_ex;
cond_resched();//增加抢占点,调度其它进程,当前里程进入睡眠
}
wait = NULL;
if (retval || timed_out || signal_pending(current))//这里就跳出循环,需要讲一下signal_pending
break;
if (table.error) {
retval = table.error;
break;
}
/*
* If this is the first loop and we have a timeout
* given, then we convert to ktime_t and set the to
* pointer to the expiry value.
*/
//读取需要等待的时间,等待超时
if (end_time && !to) {
expire = timespec_to_ktime(*end_time);
to = &expire;
}
if (!poll_schedule_timeout(&table, TASK_INTERRUPTIBLE,to, slack))
timed_out = 1;
}
poll_freewait(&table);//从等待队列头中删除poll_wait中添加的等待队列,并释放资源
return retval;//调用成功与否就看这个返回值
}
do_select大概的思想就是:当应用程序调用select() 函数, 内核就会相应调用 poll_wait(), 把当前进程添加到相应设备的等待队列上,然后将该应用程序进程设置为睡眠状态。直到该设备上的数据可以获取,然后调用wake up 唤醒该应用程序进程。
用户态程序
http://www.cnblogs.com/hnrainll/archive/2011/05/05/2038186.html
可参考的文档在百度文库里面: 《深入浅出Linux TCP IP协议栈》
发送报文:
ip_push_pending_frames
->ip_output
-> ip_finish_output
-> ip_finish_output2
-> neigh_event_send(启动定时器测试是否可达)
-> dev_queue_xmit(发送报文)
接收报文:
rx_submit(req->complete=)rx_complete
->netif_rx
->net_rx_action
->poll(process_backlog)
netif_receive_skb -> pt_prev->func(ip_rcv)
各种协议分析:
http://www.linuxidc.com/Linux/2012-04/59201.htm
TCP 发送源码分析
http://blog.chinaunix.net/uid-26675482-id-4087557.html
http://blog.chinaunix.net/uid-26675482-id-4088785.html
http://blog.chinaunix.net/uid-26675482-id-4089504.html
ARP协议:
http://blog.csdn.net/lickylin/article/details/22829969
生成树协议,如果你正在运行多个或者冗余网桥,那么你需要开启生成树协议来控制多次跳转,避免回路路由。
IPv4数据报最大大小是65536(16位) MTU,这是由硬件规定的,如以太网的MTU是1500字节 Path MTU: 指两台主机间的路径上最小MTU 分片:指IP数据包大小超过相应的链路的MTU,IPv4将对IP数据进行分片,到达目的主机后进行重组 TCP滑动窗口和缓冲区大小的关系:对于客户方,接收缓冲区的大小是该连接上所能通告的最大窗口大小,也可以理解为:客户方窗口最初设为缓冲区的大小,当接收的数据未交付应用协议时,缓冲区的一部分已用,所以窗口大小势必减小。 IP分片:物理网络层一般要限制每次发送数据帧的最大长度。任何时候IP层接收到一份要发送的IP数据包时,它要判断向本地哪个接口发送数据,并查询该接口获得其MTU。 Socket,有时,一个IP地址和一个端口号也称为一个插口。 MSS(最大报文长度),表示TCP传往另一端的最大块数据的长度。
---------------------------------------------------
标志 字符缩写 描述
---------------------------------------------------
S SYN 同步序号
F FIN 发送方完成数据发送
R RST 复位连接
P PSH 尽可能快地将数据送往接收进程
. 点 以上四个标志比特位均置0
URG 紧急指针有效
ACK 确认序号有效
------------------------------------------------------
现在很多系统都使用双机热备份系统(即一个主用,另一个备用,如果主用没有问题,备用一直处于空闲状态;如果主用出现问题,备用立刻接管)。假设主用服务器的MAC地址为:1111-1111-1111,备用服务器的MAC地址为:2222-2222-2222,通过某种软件,两台服务器对外共用一个IP,例如10.10.10.1,这样客户机在需要同服务器进行通信的时候(第一次通信时ARP的缓存是空的,或至少没有10.10.10.1的MAC地址),先向局域网发送广播ARP请求报文,请求10.10.10.1这个IP地址的MAC地址,得到主用服务器响应后,将10.10.10.1和对应的MAC地址放入自己的ARP缓存中,然后向这个IP发送请求就可以进行通信了。如果在通信的过程中,主用服务器突然发生故障,宕机了,这时备用服务器立刻接管10.10.10.1这个IP进行服务,可是刚才那台客户机的ARP缓存表中10.10.10.1这个IP对应的MAC地址是1111-1111-1111,再往这个MAC地址发送数据包肯定是石沉大海的,怎样才能让备用接管了服务之后立刻能起作用呢? 我们能想到的方法有两种,一种就是在使用双机热备份系统,接管那个IP的时候,生成一个不依赖于任何一个主机的虚拟MAC地址,接管IP的同时也接管那个虚拟的MAC地址,这样客户机不需要做任何更改动作,ARP缓存表不变。另外一种就是在接管的同时,接管的服务器对外广播一个ARP报文给所有主机,例如在刚才的例子中,ARP广播报文的数据字段中源IP地址是10.10.10.1,源MAC地址是2222-2222-2222,目的IP地址也是10.10.10.1,目的MAC地址也是2222-2222-2222,IP报文的目的地址是FFFF-FFFF-FFFF,这样让所有的广播网络上的主机接收该报文,并更新自己的ARP缓存表,已告知10.10.10.1这个IP的对应MAC地址已经变为2222-2222-2222,这样,刚才的那个客户机就能正确地同服务器进行通信了。
这种方法在大多数系统中已经被采用,例如Cisco的HSRP技术中,虚拟出来的MAC地址是以0000.0c07.ac+HSRP的group ID组成,并且限制局域网上不会存在不同应用的相同Group ID,以确保局域网上不会重复MAC地址生成。在VRRP中也是如此,原理和HSRP同。这样无论主备用如何切换,客户机不需要做任何动作。
第二种方法就是免费ARP技术(gratuitous ARP),目前应用也很广泛。 免费ARP的作用 目前,免费ARP的作用有两种。
第一种就是刚才上面所说的宣告广播的作用,以告诉整个广播域,目前这个IP所对应的MAC地址是什么。
第二种是看看广播域内有没有别的主机使用自己的IP,如果使用了,则在界面上弹出“IP冲突”字样。普通ARP请求报文广播发送出去,广播域内所有主机都接收到,计算机系统判断ARP请求报文中的目的IP地址字段,如果发现和本机的IP地址相同,则将自己的MAC地址填写到该报文的目的MAC地址字段,并将该报文发回给源主机。所以只要发送ARP请求的主机接收到报文,则证明广播域内有别的主机使用和自己相同的IP地址(这里不考虑路由器的ARP代理问题)。免费ARP的报文发出去是不希望收到回应的,只希望是起宣告作用;如果收到回应,则证明对方也使用自己目前使用的IP地址。 在所有网络设备(包括计算机网卡)up的时候,都会发送这样的免费ARP广播,以宣告并确认有没有冲突。
writev和send没有本质区别,最终都会去调用 tcp_sendmsg函数进行数据发送。唯一的区别是如果要发送32k的10个数据,writev调用一次,send需要调用10次。
writev
SYSCALL_DEFINE3(writev, ,...)
-> vfs_writev
-> do_readv_writev
-> do_sync_readv_writev
-> sock_aio_write
-> do_sock_write
-> inet_sendmsg -> tcp_sendmsg
send
SYSCALL_DEFINE4(send, ...)
-> sys_sendto
-> sock_sendmsg
-> __sock_sendmsg
->__scok_sendmsg_nosec
-> inet_sendmsg -> tcp_sendmsg
平台如下: CentOS 5.2 Linux kernel 2.6.18-92.e15 CPU: Intel(R) Pentium(R) 4 CPU 2.40GHz Disk: 7200 rpm
测试的想法是: 对于writev(), 如果有10 个buffer, 并且buffer的大小是1kb, 那么我就先依次调用write() 10 次, 每次写1KB 到同一个文件, 记录下时间, 然后记录下用writev()的时间。 最后, 以write()为baseline, 计算writev()所占的%, 如果%越小, 证明writev() 的性能就越好。
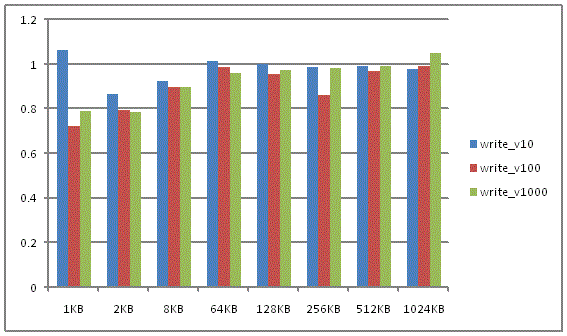
做了两组测试,
第一组, 固定buffer 的个数(10, 100, 1000), 依次增加buffer的大小, 从1KB – 1024KB, 数据如下, (基准线为相应write()的数据)例如, 10 个buffer, 每个buffer size 是1KB。 write() 耗时0.092 ms, writev() 耗时0.098 ms, 图中的数据即为 1.067 (write_v10, 1KB)
第二组, 固定buffer大小(1KB, 2KB, 8KB), 依次增加buffer的数目, 从 200 – 8000, 数据如下 (基准线为相应write()的数据)
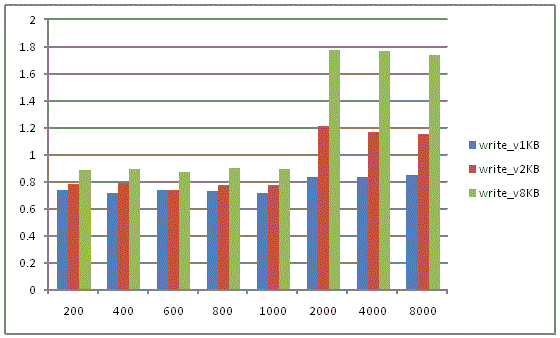
结论: writev() 应使用在small write intensive 的workload中, buffer size 应控制在 2KB 以下, 同时buffer的数目不要超过IOV_MAX, 否则 writev() 并不会带来性能的提高。
现在, 所要研究的问题是对于不同的workload, 如何快速的确定writev()中buffer的个数和大小, 从而达到较好performance。
dm9000网卡驱动完全分析
http://blog.csdn.net/ypoflyer/article/details/6209922