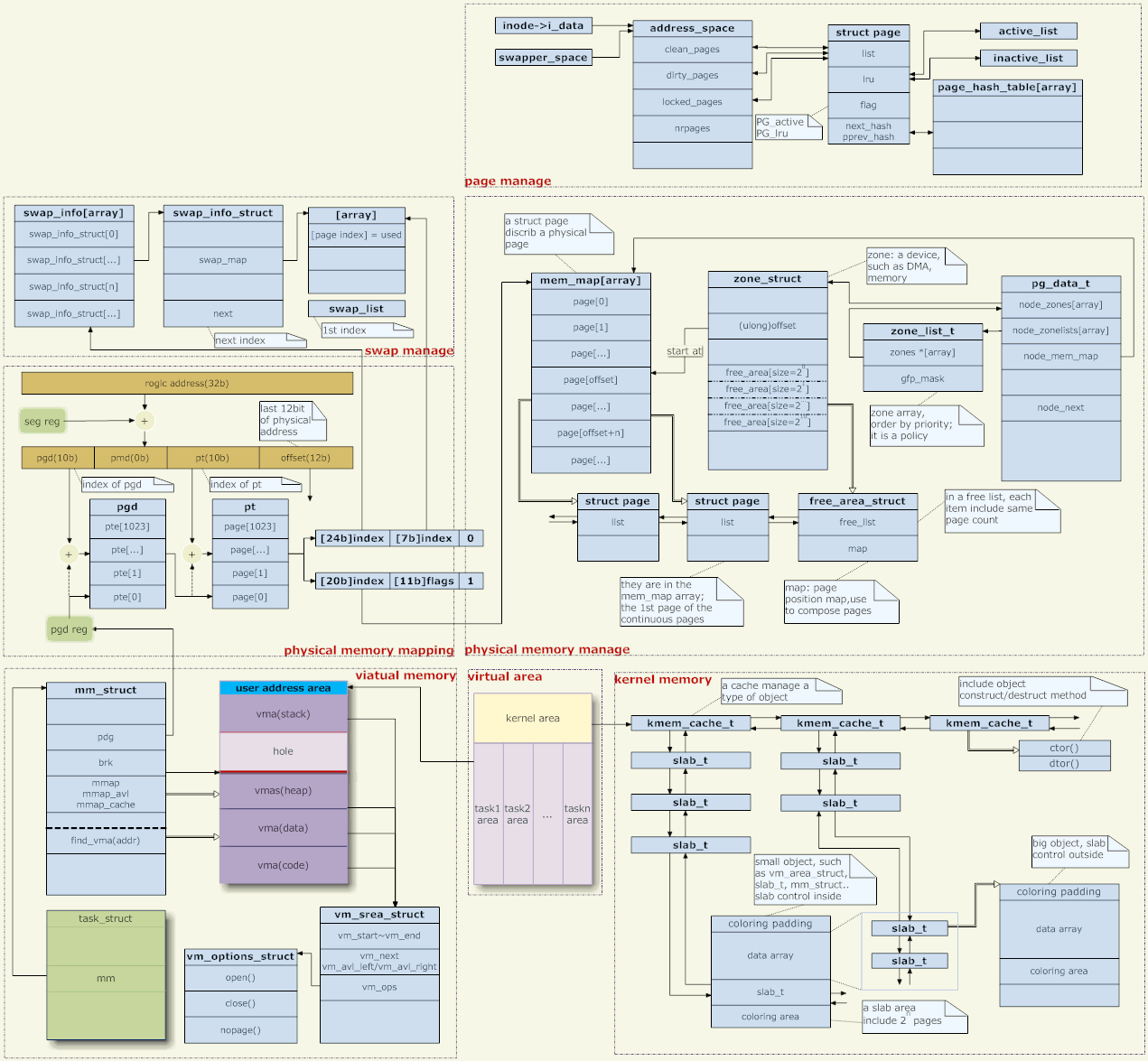
内存全景图

预备知识–程序的内存分配, 一个由 C/C++ 编译的程序占用的内存分为以下几个部分:
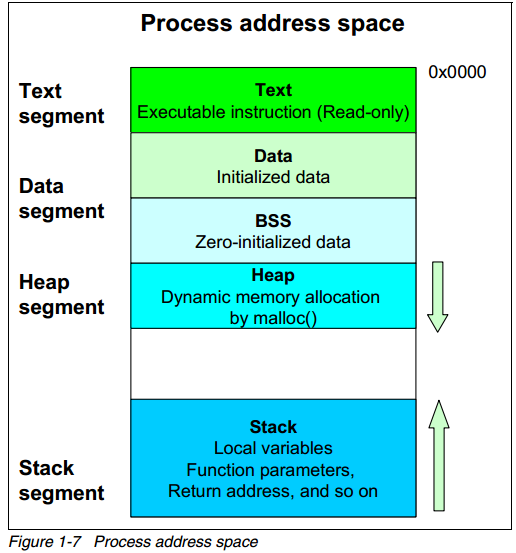
用户进程地址空间的内存地址分配可以通过 pmap命令查看。你也可以通过ps命令显示总的段大小。 这是一个前辈写的,非常详细
//main.cpp
int a = 0; 全局初始化区
char *p1; 全局未初始化区
main()
{
int b; 栈
char s[] = "abc"; 栈
char *p2; 栈
char *p3 = "123456"; 123456\0在常量区,p3在栈上。
static int c =0; 全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); 123456\0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
}
http://blog.csdn.net/sgbfblog/article/details/7772153
http://blog.163.com/xychenbaihu@yeah/blog/static/132229655201311884819764/
默认情况下,malloc函数分配内存,如果请求内存大于128K(可由M_MMAP_THRESHOLD选项调节),那就不是去推_edata指针了,而是利用mmap系统调用,从堆和栈的中间分配一块虚拟内存。
当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)。
http://blog.csdn.net/dog250/article/details/6243276
http://www.kerneltravel.net/journal/v/mem.htm
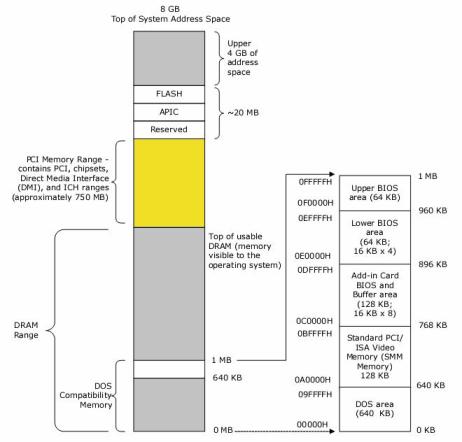
硬件平台可以粗略地划分成三个部分:CPU、内存和其他硬件设备。其中,CPU是平台的主导者,从CPU的角度来看,内存和其他硬件 设备都是可以使用的资源。这些资源组合在一起,分布在CPU的物理地址空间内。CPU使用物理地址索引这些资源。物理地址空间的大 小由CPU实现的物理地址位数所决定,物理地址位数和CPU处理数据的能力(CPU的位数)没有必然的联系,例如 16位的CPU具有20位 空间。
所谓的地址总线32位是指从cpu引脚出来的总线是32位,是针对于cpu而言的,具体这些总线最终能全部连接在主板的ram上吗?会不会还会连接到其它的设备上呢?这要看主板怎么设计了。这里主板上的北桥芯片解除了cpu和设备之间的地址偶合,典型的设计为cpu出来的地址总线32位全部连接在北桥芯片之上,当cpu发出一个32位的地址比如0xcb000000的时候,由北桥来决定该地址发往何处,可能发往内存ram,也可能发往显示卡,也可能发往其它的二级总线,当然也可能发往南桥芯片(一个类似的解析地址的芯片,北桥解耦了cpu和主板芯片/总线,而南桥则解耦了主板芯片/总线和外部设备,比如ata硬盘,usb之类的设备就可以连接在南桥芯片上)。如果北桥选择将该地址发往PCI总线上,那么显然内存ram就收不到这个地址请求,而且自从主板设计好了之后,理论上该地址就永远被发送给了PCI,当然了,你可以通过诸如跳线之类的办法来更改之,(而且现在很多板子都有被bios“自动探测/识别/设置”的功能,此种情形下地址拓扑信息就不必记录在bios里面了,而是在bios开始运行的时候自动生成,生成的方式不外乎侦测-往特定针脚发送电平序列信号,然后得到回复,不过具体往哪里发送电平信息也必须由主板和cpu来确定标准),因此虽然你有4G的所谓的满载的ram,然而它的地址0xcb000000却不能被使用。以上仅仅是一个例子,主板上还有很多的设备或者总线会占据一些地址总线上的地址,这样说来你的4G的ram会有很多不能使用,典型的,intel提出了PAE,即物理地址扩展,使得可以支持4G以上的ram,实际上它的实现很简单,就是为ram增加几个地址总线位,变成36位的地址总线,这样就可以插入64G的ram了,这时4G以上的地址总线空间将不会被其它设备占据,而北桥只会将地址发往ram。
既然4G的地址空间不能完全由ram内存条使用,那么ram不能使用哪些地址呢?这个信息很重要,因为这个信息会指导操作系统内核进行物理内存分配,比如其它地址使用的地址处的页面就不能被分配,否则就访问到设备了,因此这些个地址处的页面应该设置为保留,永远不能被使用,事实上,它们被浪费了。这些地址信息存放的位置是BIOS,BIOS里面存放着很重要的信息,这些信息可以组成一张逻辑拓扑图,真实反映主板上的芯片是如何排列放置的,待到主板上电后,主板上的芯片和总线就形成了一张真实的“地图”,在bios拓扑图的指导下被检测。
既然BIOS里面存放拓扑图,那么操作系统内核在启动的时候怎样得到它呢,得到了它之后,操作系统才能建立自己的物理地址空间映射。得到bios信息的办法莫多于bios调用了,也就是0x15调用,参数由寄存器指定,如果你想得到地址信息,也就是那张拓扑图,那么你要将eax设置成0X0000E820,然后读取返回即可,以下是linux在拥有256M内存的机器上得到的地址信息,该信息在内核启动的时候通过bios调用得到,显然所有的ram都可以使用,毕竟它太小了。下面是一个拥有4G内存的机器的地址信息:
BIOS-provided physical RAM map:
BIOS-e820: 0000000000000000 - 000000000009f000 (usable)
BIOS-e820: 000000000009f000 - 00000000000a0000 (reserved)
BIOS-e820: 00000000000f0000 - 0000000000100000 (reserved)
BIOS-e820: 0000000000100000 - 00000000bdc90000 (usable)
BIOS-e820: 00000000bdc90000 - 00000000bdce3000 (ACPI NVS)
BIOS-e820: 00000000bdce3000 - 00000000bdcf0000 (ACPI data)
BIOS-e820: 00000000bdcf0000 - 00000000bdd00000 (reserved)
BIOS-e820: 00000000e0000000 - 00000000f0000000 (reserved)
BIOS-e820: 00000000fec00000 - 0000000100000000 (reserved)
BIOS-e820: 0000000100000000 - 0000000140000000 (usable)
可见0000000000100000 - 00000000bdc90000总共3G左右的ram是可以被OS使用的,它们是可以被寻址的,而其它的将近1G的ram被设置为reserved,它们被浪费了。在linux的/proc/meminfo中MemTotal:一行所显示的就是0x00000000bdc90000和0000000000100000的差,具体这些地址被用于什么设备,从/proc/iomem中可以看到,以下是256M内存机器的iomem:
00000000-0000ffff : reserved
00010000-0009f7ff : System RAM
0009f800-0009ffff : reserved
000a0000-000bffff : Video RAM area
000c0000-000c7fff : Video ROM
000c8000-000c8fff : Adapter ROM
000c9000-000c9fff : Adapter ROM
000ca000-000cafff : Adapter ROM
000dc000-000dffff : reserved
000e4000-000fffff : reserved
000f0000-000fffff : System ROM
00100000-0feeffff : System RAM
01000000-01242d96 : Kernel code
01242d97-0133c847 : Kernel data
01394000-013cc243 : Kernel bss
0fef0000-0fefefff : ACPI Tables
0feff000-0fefffff : ACPI Non-volatile Storage
0ff00000-0fffffff : System RAM
10000000-1000ffff : 0000:00:11.0
10010000-1001ffff : 0000:00:12.0
10020000-1002ffff : 0000:00:13.0
10030000-10037fff : 0000:00:0f.0
10038000-1003bfff : 0000:00:10.0
e8000000-e87fffff : 0000:00:0f.0
e8800000-e8800fff : 0000:00:10.0
f0000000-f7ffffff : 0000:00:0f.0
fec00000-fec0ffff : reserved
fec00000-fec00fff : IOAPIC 0
fee00000-fee00fff : Local APIC
fee00000-fee00fff : reserved
fffe0000-ffffffff : reserved //这里一般是bios,凡是cpu发出的到这些地址的访问,全部被路由到bios
再次重申一遍,是4G以下的某些地址预留给了设备而不是4G以下的ram预留给了设备,很多设备是不使用ram芯片作存储的,它们只是占用了一些地址而已。比如上述iomem的内容中000c8000-000c8fff : Adapter ROM就是将前面的地址预留给了ROM芯片,cpu发出对该地址段中的一个的访问时,芯片组会将地址总线信号发往ROM而不是内存ram。
在linux中,内核启动的时候,在很早的阶段,内核调用detect_memory来通过bios探测内存,它又调用detect_memory_e820来探测地址信息:
static int detect_memory_e820(void)
{
int count = 0;
struct biosregs ireg, oreg;
struct e820entry *desc = boot_params.e820_map;
static struct e820entry buf; /* static so it is zeroed */
initregs(&ireg);
ireg.ax = 0xe820;
ireg.cx = sizeof buf;
ireg.edx = SMAP;
ireg.di = (size_t)&buf;
do {
intcall(0x15, &ireg, &oreg); //调用bios中断
ireg.ebx = oreg.ebx;
if (oreg.eflags & X86_EFLAGS_CF)
break;
if (oreg.eax != SMAP) {
count = 0;
break;
}
*desc++ = buf;
count++;
} while (ireg.ebx && count < ARRAY_SIZE(boot_params.e820_map));
return boot_params.e820_entries = count;
}
这个函数调用完毕之后,boot_params.e820_map中就保存了“哪段地址是干什么用”的信息,将来linux在初始化物理内存的时候将使用这个信息,比如将保留给设备的地址处的页面设置为reversed,这样在分配物理页面的时候,会绕过这些被保留的地址处的页面。 附:察看linux中的内存的问题在linux中可以通过top,free,/proc/meminfo等多种方式查看系统的内存,然而不同的内核编译选项编译出来的内核显示出来的内存总量却是不同的,在编译了HIGHMEM64G,也就是打开了PAE的情况下编译的内核,查到的内存总量会包括预留地址处的内存页面,而不打开PAE则不计算这些页面,显然打开PAE时的计算方式是不合理的,毕竟既然有那么多内存就应该可被使用,而实际上那些页面是不能使用的。
附:x86体系的地址映射图(注意,是地址,而不是ram)
内核用 struct page 结构表示系统中的每个物理页。内核仅仅用这个数据结构来描述当前时刻的物理页中存放的东西。这种数据结构的目的在于描述物理内存本身,而不是描述包含在其中的数据。
struct page{
unsigned long flags; // 存放页的状态,包括页是不是脏的,是不是被锁定在内存中等。
atomic_t _count; // 存放页的引用计数,也就是这一页被引用了多少次。
address_space *mapping; //指向和这个页关联的 address_space 对象。
void *virtual; // 是页的虚拟地址,通常情况下,它就是页在虚拟内存中的地址。有些内存(即所谓的高端内存)并不永久地映射到
// 内核地址空间上。这种情况下,改值为 NULL,需要的时候,必须动态地映射这些页。
}
三个内存管理区:
高端内存是指物理地址大于 896M 的内存。对于这样的内存,无法在“内核直接映射空间”进行映射。因为“内核直接映射空间”最多只能从 3G 到 4G,只能直接映射 1G 物理内存,对于大于 1G 的物理内存,无能为力。实际上,“内核直接映射空间”也达不到 1G, 还得留点线性空间给“内核动态映射空间” 呢。因此,Linux 规定“内核直接映射空间” 最多映射 896M 物理内存。
对于高端内存,可以通过 alloc_page() 或者其它函数获得对应的 page,但是要想访问实际物理内存,还得把 page 转为线性地址才行,也就是说,我们需要为高端内存对应的 page 找一个线性空间,这个过程称为高端内存映射。 高端内存映射有下两种:
永久内存映射允许建立长期映射。使用主内核页表中swapper_pg_dir的一个专门页表。
kmap 函数来实现。这个函数在高端内存或低端内存上都能使用。如果 page 结构对应的是低端内存中的一页,函数只会单独地返回该页的虚拟地址。如果页位于高端内存,则会建立一个永久映射,再返回地址。该函数可以睡眠,因此 kmap 只能用在进程上下文中。
可以用在中断处理函数和可延迟函数的内部,从不阻塞。因为临时内存映射是固定内存映射的一部分,一个地址固定给一个内核成分使用。
通过下列函数建立一个临时映射 kmap_atomic
每个CPU都有自己的一个13个窗口(一个线性地址及页表项)的集合。
enum km_type {
KM_BOUNCE_READ,
KM_SKB_SUNRPC_DATA,
KM_SKB_DATA_SOFTIRQ,
KM_USER0,
KM_USER1,
KM_BIO_SRC_IRQ,
KM_BIO_DST_IRQ,
KM_PTE0,
KM_PTE1,
KM_IRQ0,
KM_IRQ1,
KM_SOFTIRQ0,
KM_SOFTIRQ1,
KM_TYPE_NR
};
该函数分配 2^order 个连续的物理页,并返回一个指针,该指针指向第一个页的 page 结构体。
这个函数与 alloc_pages 作用相同,不过它直接返回所请求的第一个页的逻辑地址。因为也是连续的,所以其他页也会紧随其后。
kmalloc 函数与用户空间的 malloc 一族函数非常相似,只不过它多了一个 flags 参数。kmalloc 函数是一个简单的接口,用它可以获得以字节为单位的一块内核内存。如果你需要整个页,那么前面的页分配接口可能是更好的选择。
vmalloc 函数的工作方式类似于 kmalloc , 只不过前者分配的内存虚拟地址是连续的,而物理地址则无须连续。这也是用户空间分配函数的工作方式。kmalloc 函数确保页在物理地址上是连续的。
尽管在某些情况下才需要得到物理地址连续的内存。但是,很多内核代码都用 kmalloc 来获得内存,而不是vmalloc 。这主要是出于性能的考虑。vmalloc 函数为了把物理上不连续的页转换为虚拟地址空间上连续的页,必须专门建立页表项。糟糕的是,通过 vmalloc 获得的页必须一个个地进行映射。这就导致比直接内存映射大得多的 TLB 抖动。故仅在不得已的时候使用。
https://www.ibm.com/developerworks/cn/linux/l-linux-slab-allocator/index.html
与传统的内存管理模式相比, slab 缓存分配器提供了很多优点。首先,内核通常依赖于对小对象的分配,它们会在系统生命周期内进行无数次分配。slab 缓存分配器通过对类似大小的对象进行缓存而提供这种功能,从而避免了常见的碎片问题。slab 分配器还支持通用对象的初始化,从而避免了为同一目而对一个对象重复进行初始化。最后,slab 分配器还可以支持硬件缓存对齐和着色,这允许不同缓存中的对象占用相同的缓存行,从而提高缓存的利用率并获得更好的性能。对于小型的嵌入式系统来说,存在一个 slab 模拟层,名为 SLOB。
slub 内存分配:linux-slub.docx
kmem_getpages 分配整页
kmem_cache_create 创建高速缓存
kmem_cache_alloc 分配高速缓存
proc 文件系统提供了一种简单的方法来监视系统中所有活动的 slab 缓存。这个文件称为 /proc/slabinfo,它除了提供一些可以从用户空间访问的可调整参数之外,还提供了有关所有 slab 缓存的详细信息。当前版本的 slabinfo 提供了一个标题,这样输出结果就更具可读性。对于系统中的每个 slab 缓存来说,这个文件提供了对象数量、活动对象数量以及对象大小的信息(除了每个 slab 的对象和页面之外)。另外还提供了一组可调整的参数和 slab 数据。 要调优特定的 slab 缓存,可以简单地向 /proc/slabinfo 文件中以字符串的形式回转 slab 缓存名称和 3 个可调整的参数。下面的例子展示了如何增加 limit 和 batchcount 的值,而保留 shared factor 不变(格式为 “cache name limit batchcount shared factor”):
# echo "my_cache 128 64 8" > /proc/slabinfo
limit 字段表示每个 CPU 可以缓存的对象的最大数量。 batchcount 字段是当缓存为空时转换到每个 CPU 缓存中全局缓存对象的最大数量。 shared 参数说明了对称多处理器(Symmetric MultiProcessing,SMP)系统的共享行为。 注意您必须具有超级用户的特权才能在 proc 文件系统中为 slab 缓存调优参数。
每个进程的内核栈大小既依赖体系结构,也与编译时的选项有关。历史上,每个进程都有两页的内核栈。因为32位和64位体系结构的页面大小分别是 4KB 和 8KB,所以通常它们的内核栈的大小分别是 8KB和16KB.
前言,本案例分析s2lm遇到的CPU飙升问题,深入研究Linux的内存回收、分配机制、分析内存碎片和CPU飙升原因。并提出将SD卡录像使用的cache从系统的cache中抽取出来进行管理的方案来解决内存碎片问题.
查看top:
Linux为了解决内存碎片问题,使用了伙伴算法来管理内存。所有的内存分配函数只有一个入口函数,就是 __alloc_pages_nodemask,来看下它的执行流程:
1__alloc_pages_nodemask
2 -> get_page_from_freelist
3 N-> wake_all_kswapd
4 -> __perform_reclaim
5 -> get_page_from_freelist
6 N-> should_oom
7 N-> shoud_alloc_retry
8 N-> warn_alloc_failed
9 Y-> oom
10 Y-> success
11 Y-> success
1 get_page_from_freelist
2 -> zone_writemark_ok
3 Y-> buffered_rmqueue
4 -> success
5 N-> fail
从代码看,zone_watermark_ok 除了检查申请后的 free 页面个数是否在水线以下,还会检查申请后的各个 order的 free的比例情况,也就是红框区域的代码。举个例子,如果目前
free=2256 pages mark=489 order=3 free_area[0]=1107 =1107 =1107 pages free_area[1]=300 =3002 =600 pages free_area[2]=123 =1234 =492 pages free_area[3]=7 =7*8 =56 pages
这种情况下申请完一个 order 为3的页面后 order>=1的页面个数为 2256-8-1107=1141 > 489/2,order>=2的页面个数为 1141-600=541>489/4,order>=3的页面个数为 541-492=49<489/8,此时认为在申请完 order 为 3的内存块后,order >=3 的内存块的比例偏小,需要回收内存来平衡。
我们怀疑是内存碎片,查看碎片情况,虽然 free 内存还很多,但是 order=2以上的内存块已经没有了,碎片的情况已经比较严重了
cat /proc/buddyinfo Node 0, zone Normal 931 1337 11 0 0 0 0 0 0 0 0
原因应该是内存碎片引起内存区域不平衡,从而需要通过回收内存去平衡,当碎片化严重时,可能会导致代码段被回收,当代码段被锁住后,也就没有能够再可以回收的内存了,从而导致内存申请失败,此时需要一直尝试回收并重新申请,从而引起 CPU 上升。
先来看下内存碎片是怎么产生的。Linux内存碎片分为两种,一种是内存碎片,是指那种内存申请出去了,当实际没有使用到的情况。比如你申请了 106个字节,系统会实际分给你 128 个字节,这相差的 22 字节就属于內部碎片。另外一种是外部碎片,是指那种内存没有分配出去,但是实际上可能分配不出去的情况。比如以下情况:
---------------------------------------------
| 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
---------------------------------------------
虽然 free 有 9个 pages,但是已经无法满足连续 4 个 page的需求了,如果这些申请出去的内存可以回收,那还是能够满足需求的,如果这些申请出去的内存不可回收,那么将会永远申请不到连续4个 page 的内存。
上面讲到了要解决内存碎片问题,可以从 cache 入手,我的想法是如果把 sd 卡录像使用的 cache 从系统 cache 中分离出来,进行预分配,并且由自己进行甘利,就如前面所讲的,把不能回收的和能够回收的内存分开管理。
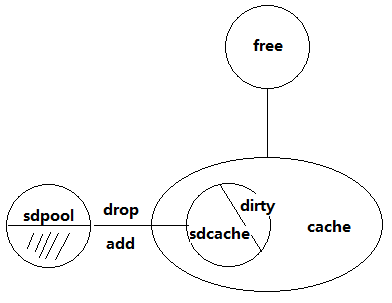
设计思路,如上图所示: 创建一个内存池,写 sd 卡时从池中申请页面用于 cache,当池中的页面个数小于一半时,释放 cache还回池中,但不还给操作系统。
只要能够找到申请和释放 cache 的人口就能够实现以上方案,因此必须搞清楚 sd 卡读写过程
read/write
------------
vfs
------------
fat 文件系统
------------
映射层
------------
提交IO操作,生成请求,插入到磁盘的请求队列中
------------
cache结构:grab_cache_page_write_begin->__page_cache_alloc
总结:Cache虽然可以提高硬盘读者的性能,但是确实会存在引起内存碎片问题,因为cache申请的内存分散开导致没有整片的内存!
comments: 清理Cache /proc/sys/vm/drop_caches –sync,将脏数据写入磁盘
fp = fopen(“/proc/self/maps”, “r”); fgets(line, sizeof(line), fp); sscanf(line, “%08x-%08x”, &addrStart, &addrEnd); ret = mlock((void *)addrStart, addrEnd-addrStart); 一定要读一下内存
反向映射
www.cnblogs.com/zhaoyl/p/3695517.html
www.tuicool.com/articles/JRJjQji
页面回收及反射机制
http://os.51cto.com/art/201103/249879_3.htm
slab 分配器
http://blog.csdn.net/vanbreaker/article/details/7671618
http://www.ilinuxkernel.com/files/Linux_Physical_Memory_Page_Allocation.pdf Linux_Physical_Memory_Page_Allocation.pdf